About Me
I am currently a senior researcher at Meituan, leading an effort on application and research of GenAI and foundation models. Previously, I worked as a senior researcher at Huawei and a researcher at Sensetime Research.
I obtained my Ph.D. degree from University of Science & Technology of China (USTC). During my graduate study, I spent a wonderful time at Multimedia Lab (MMLab), Chinese University of Hong Kong, under the supervision of Prof. Xiaogang Wang.
My research interests focus on multimodal & foundation models, Agentic Learning and AIGC, as well as their applications in industry.
** Positions are available for highly self-motivated full-time researchers, engineers and interns!
** Looking for long-term collaborations on research in the fields of Agent, foundation models and GenAI!
News
- ** Looking for long-term collaborations on research in the fields of foundation models, Agent, RL and GenAI!
- ** Positions are available for highly self-motivated full-time researchers, engineers and interns!
- [2026/06] We release TAPO for multimodal search agents, our discussion on OPD method TOPD, and VistaHop for visual deep search benchmarking.
- [2026/05] We release three papers on RL for LLM training: Joint Training MTP, ZipRL, and When Self-Belief Misleads.
- [2026/05] We release the token-level credit assignment method AMR-SD.
- [2026/05] We release the tool-integrated reasoning method Implicit Hierarchical GRPO.
- [2026/05] Two papers (CDRRM and LocalSearchBench) are accepted to KDD 2026.
- [2026/05] Recognized as Gold Reviewer for ICML 2026.
- [2026/05] We release the benchmark for reward modeling RecRM-Bench.
- [2026/05] New homepage launched.
- [2026/05] Six papers are accepted to ICML 2026.
- [2026/04] We release the self-distillation for deep search π-Play.
- [2026/04] Three papers are accepted to ACL 2026 (One Main and two findings).
- [2026/01] Seven papers are accepted to ICLR 2026 (Six mains and one workshop).
- [2025/12] We release Local Search Benchmark for agentic search LocalSearchBench.
- [2025/11] Our paper for Verifiable Stepwise Reward is accepted to AAAI 2026.
- [2025/08] Three papers are accepted to EMNLP 2025 (Two mains and one findings).
- [2025/06] Our Agentic RL framework RL Factory is released!
Recent Research
RL-Driven Post-Training Pipeline
Closed loop: Evaluate gaps → Design rewards → Optimize policy → Train agents → Deploy applications → Evaluate again
benchmarks reveal gaps
→
gaps motivate reward design
Evaluation & Benchmarks
Reasoning Benchmarks
Multi-hop visual reasoning · agentic search · logical consistency
VistaHop (multi-hop visual) · LocalSearchBench (agentic search) · LogiCon (logic eval)
Rec / Multimodal Bench
RM quality for rec · dietary perception · complexity scaling
RecRM (rec reward eval) · DiningBench (dietary) · Complexity (scaling)
Reward Design
Label-Free RM
Self-supervised / latent / VL alignment rewards — no human labels needed
SSL4RL (self-supervised) · RLLR (latent reward) · RCLIP (VL reward) · CDRRM (contrastive rubric)
Active & Stepwise
Per-step verifiable reward · active hard case selection · critique-as-reward
CARE (active explore) · Stepwise (step reward) · CARD (critique reward)
Multi-Dim Fusion
Adaptive multi-reward weighting by training stage
AWPO (adaptive weight) · ZipRL (multi-dim)
reward signals
↓
feed policy training
Policy Optimization
GRPO Bias Correction
Down-weight high-advantage · debiased group-relative estimator
HA-DW (advantage downweight) · GRA-Biased (bias analysis)
Sampling Strategy
Bandit-style adaptive rollout · negative sample residual RL
Ctx Bandits (adaptive rollout) · ResRL (negative projection)
SFT+RL Fusion & Curriculum
Single-stage joint training · difficulty-aware curriculum
SRFT (joint SFT+RL) · HiDiffTIR (difficulty curriculum)
Token-Level Credit
Reshape tool-token gradients · meta-reflective credit assignment
ResT (tool-token gradient) · AMR-SD (self-distill credit)
optimized policy
↓
trains agents + efficient deployment
Agent Training
RL Framework
Plug-and-play multi-turn tool RL · modular env/reward/policy
RLFactory (modular agent RL)
Domain Agents
Adaptive search depth · audited self-play · multi-turn SQL · multi-image vision
AutoSearch (search depth) · OASP (audited self-play) · CARD (dense process reward) · MTIR (SQL agent) · IMAgent (multi-image)
Data Synthesis
Synthetic tool-use data w/o real APIs · controllable env complexity
ToolForge (synthetic trajectories) · ToolFoundry (env synthesis)
Agent Memory
Trainable graph memory · temporal memory · episodic-parametric · boundary-aware skill
Graph Memory (strategy graph) · Temporal (time-aware) · UniMem (episodic→parametric) · When Not to Imitate (skill boundary)
Efficiency
Knowledge Distillation
Online policy distill during RL · privileged self-play
POPD (online distill) · π-Play (privileged self-play)
Inference Speedup
Polar KV-cache 2-bit quant · speculative decode · overthinking control
PolarQuant (KV quant) · Spec.Decode (domain-adaptive) · OCC (overthink ctrl) · PACE (efficient reasoning)
Interpretability
RL-guided ensemble routing · SAE predicts transferability
RLAE (ensemble routing) · SAE (transfer predict) · Expert Mono (monotonicity)
agents + efficiency
↓
deploy to real tasks
Applications
Complex Reasoning
Sparse multi-agent debate · graph agentic probing
MAD-Logic (logic debate) · GRASP (graph reasoning)
Code & UI
Topology-evolving code gen · multi-agent UI orchestration
AgentConductor (code topology) · UIOrchestra (UI multi-agent)
Rec & Personalization
Behavioral semantic alignment · token-level personalization · tag-guided RL · latent nutrition
SemanticConv (rec alignment) · Rethinking (token personal.) · TagPR (tag RL) · ViPER (visual self-evolve) · LatentNutri (latent nutrition)
↑
application results validate via benchmarks → identify new gaps → cycle repeats
↑
Eval → Reward: gaps drive design
Reward → Policy: signals feed training
Policy → Agent: fine-grained credit enables tool-use
Agent → App: deploy agents
Efficiency → App: enables serving
App → Eval: validate & find new gaps
Publications
* Equal contribution # Corresponding author
Preprints & Under Review
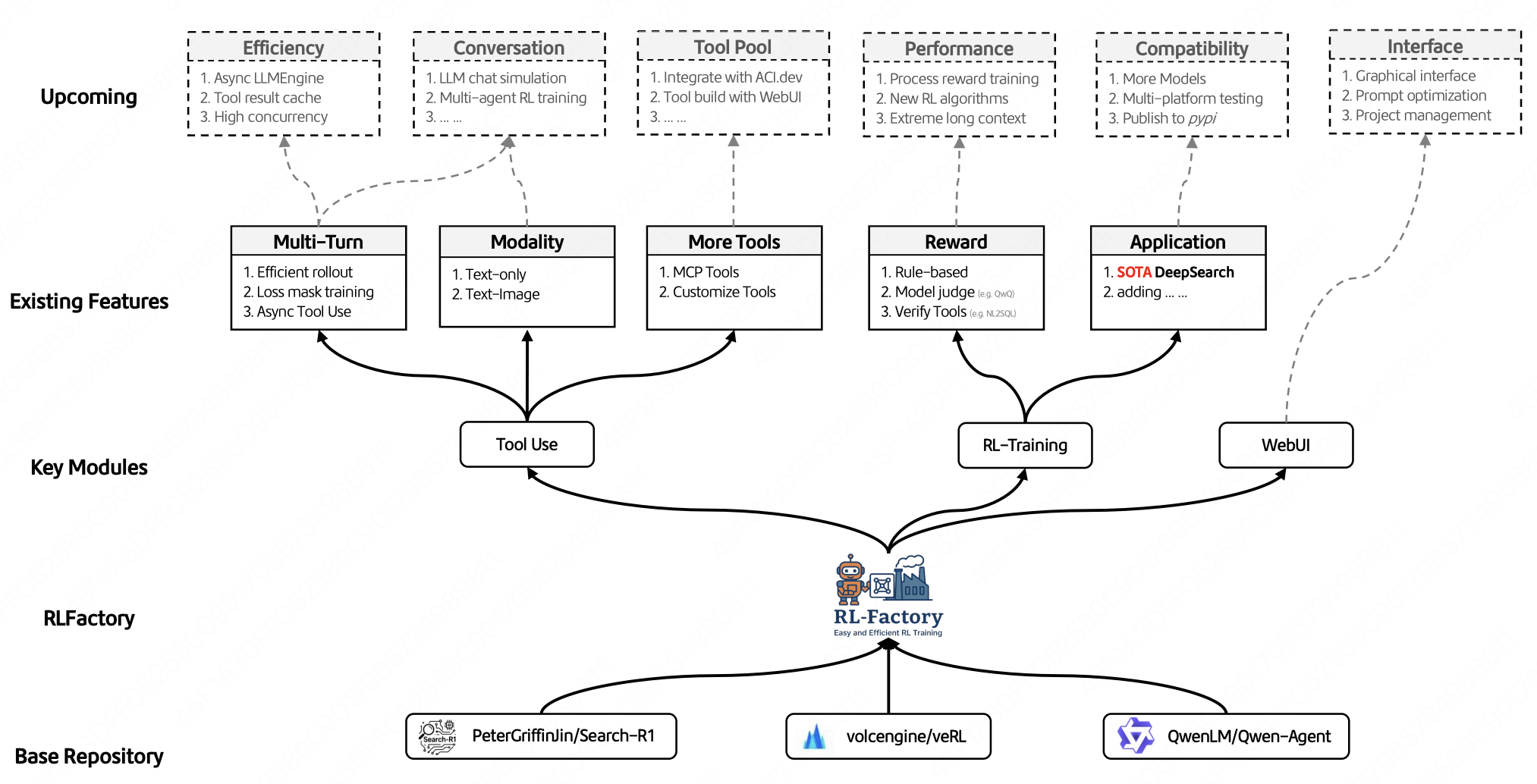
RLFactory: A Plug-and-Play Reinforcement Learning Post-Training Framework for LLM Multi-Turn Tool-Use
Jiajun Chai*, Guojun Yin*, Chengqi Dong, Hang He, Yi Jia, Jiwen Jiang, Xiaoguang Li, Xiaohan Wang, Siyu Xia, Zekun Xu, Chuhuai Yue, Wei Lin
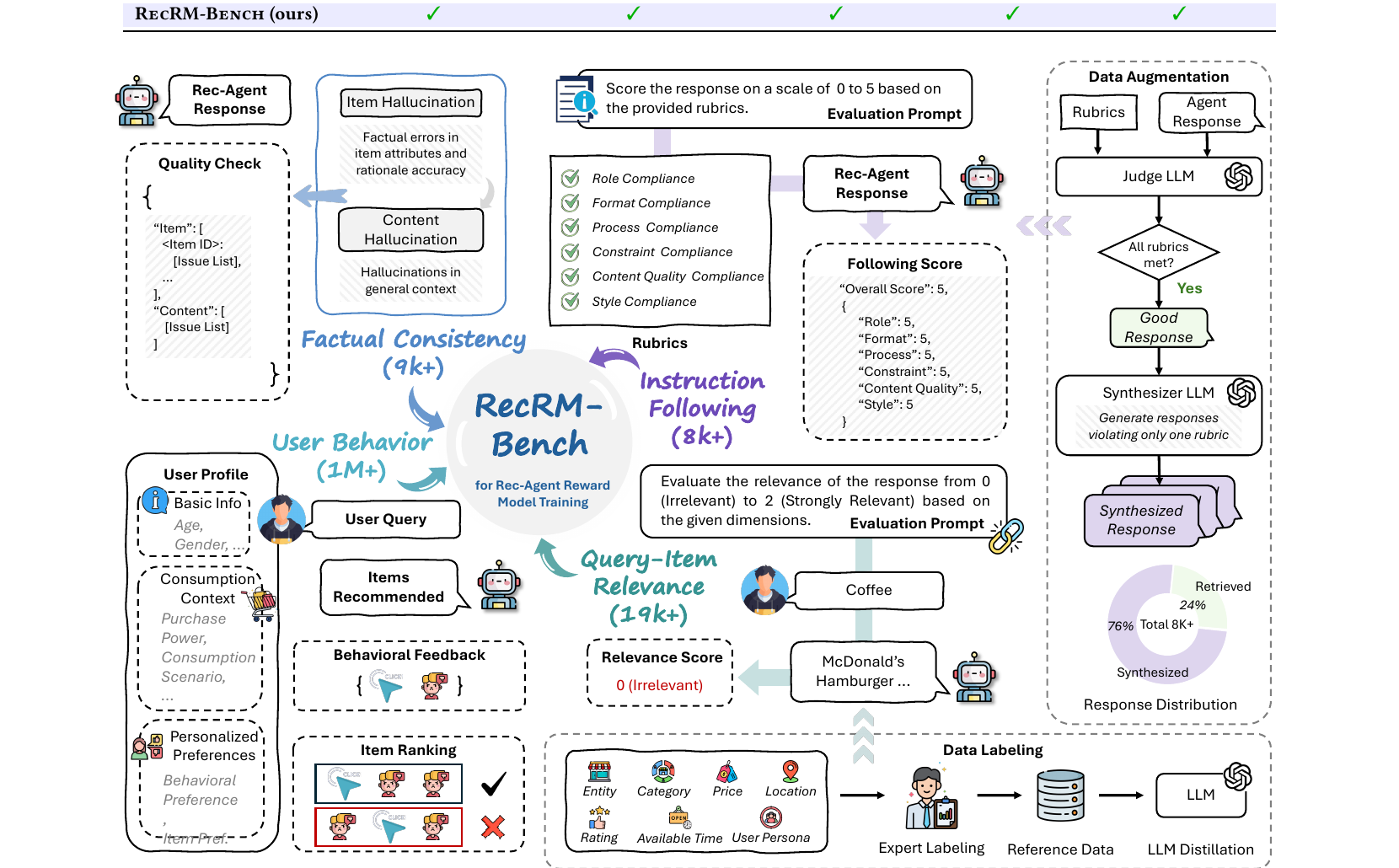
RecRM-Bench: Benchmarking Multidimensional Reward Modeling for Agentic Recommender Systems
Wenwen Zeng*, Jinhui Zhang*, Hao Chen*, Zhaoyu Hu, Yongqi Liang, Jiajun Chai, Dengcan Liu, Zhenfeng Liu, Shurui Yan, Minglong Xue, Xiaohan Wang, Wei Lin, Guojun Yin#
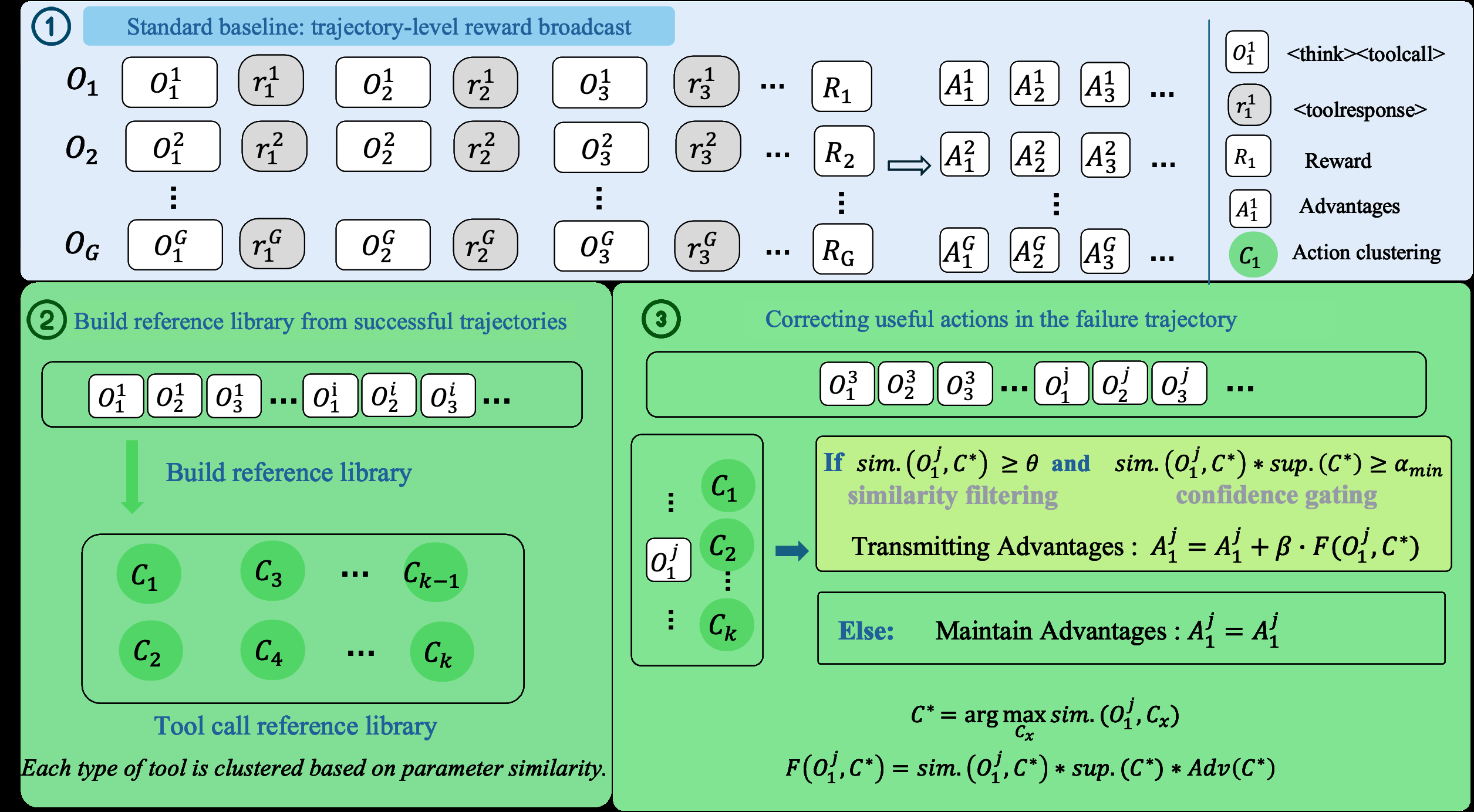
TAPO: Tool-Aware Policy Optimization via Credit Transfer for Multimodal Search Agents
Chengqi Dong, Chuhuai Yue, Hang He, Yandong Liu, Fenghe Tang, S Kevin Zhou, Xiaohan Wang, Jiajun Chai, Guojun Yin
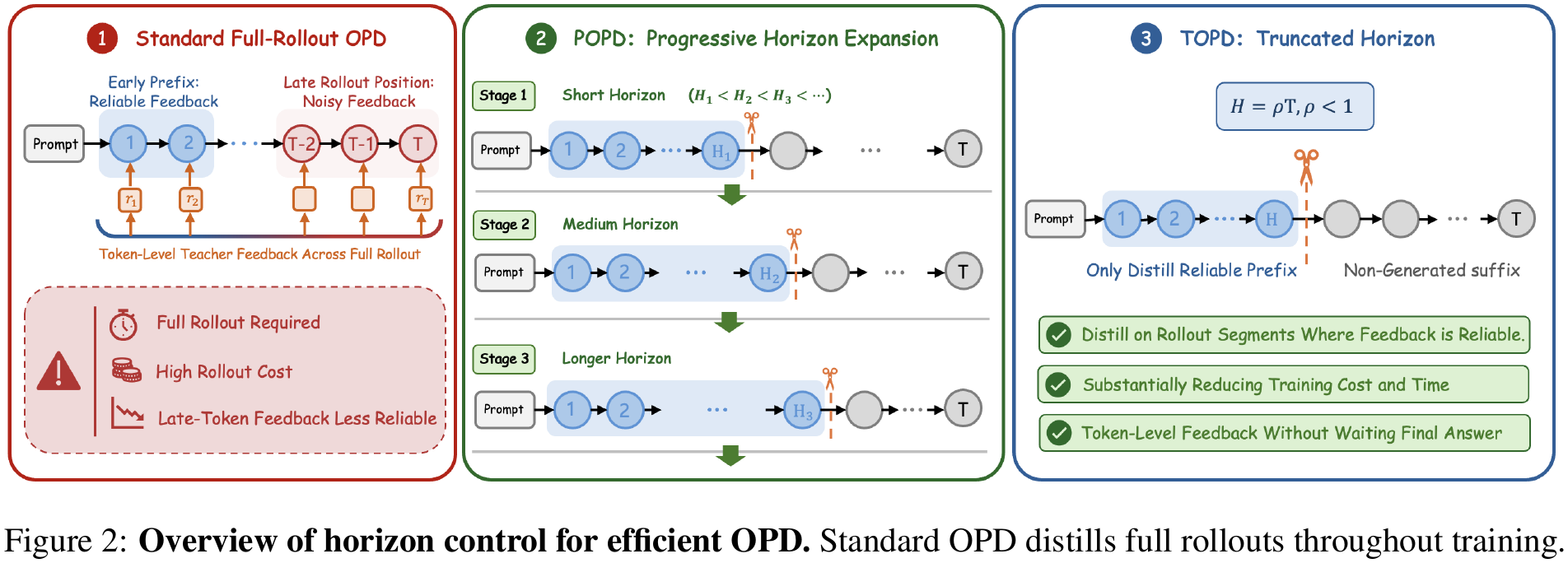
Are Full Rollouts Necessary for On-Policy Distillation?
Yaocheng Zhang*, Jiajun Chai, Yuqian Fu, Songjun Tu, Xiaohan Wang, Wei Lin, Guojun Yin, Qichao Zhang, Yuanheng Zhu, Dongbin Zhao

VistaHop: Benchmarking Multi-hop Visual Reasoning for Visual DeepSearch
Hang He, Chuhuai Yue, Chengqi Dong, Chengcheng Wan, Ting Su, Haiying Sun, Jiajun Chai, Xiaohan Wang, Guojun Yin#
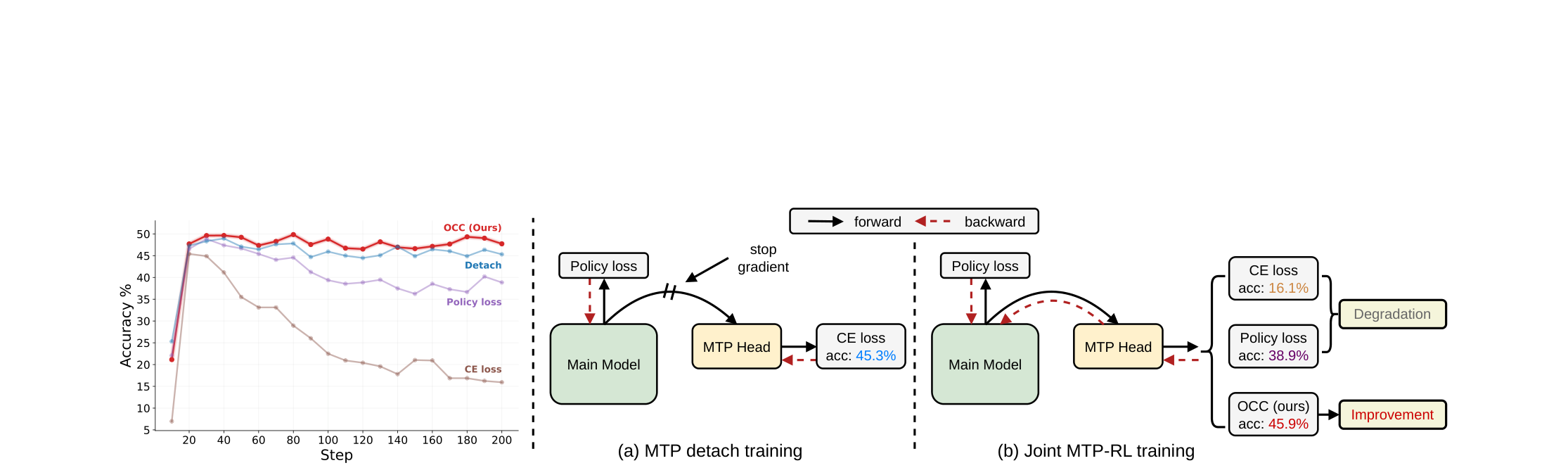
Joint Training of Multi-Token Prediction in Reinforcement Learning via Optimal Coefficient Calibration
Zili Wang*, Jiajun Chai, Lin Chen, Xiaohan Wang, Shiming Xiang, Guojun Yin
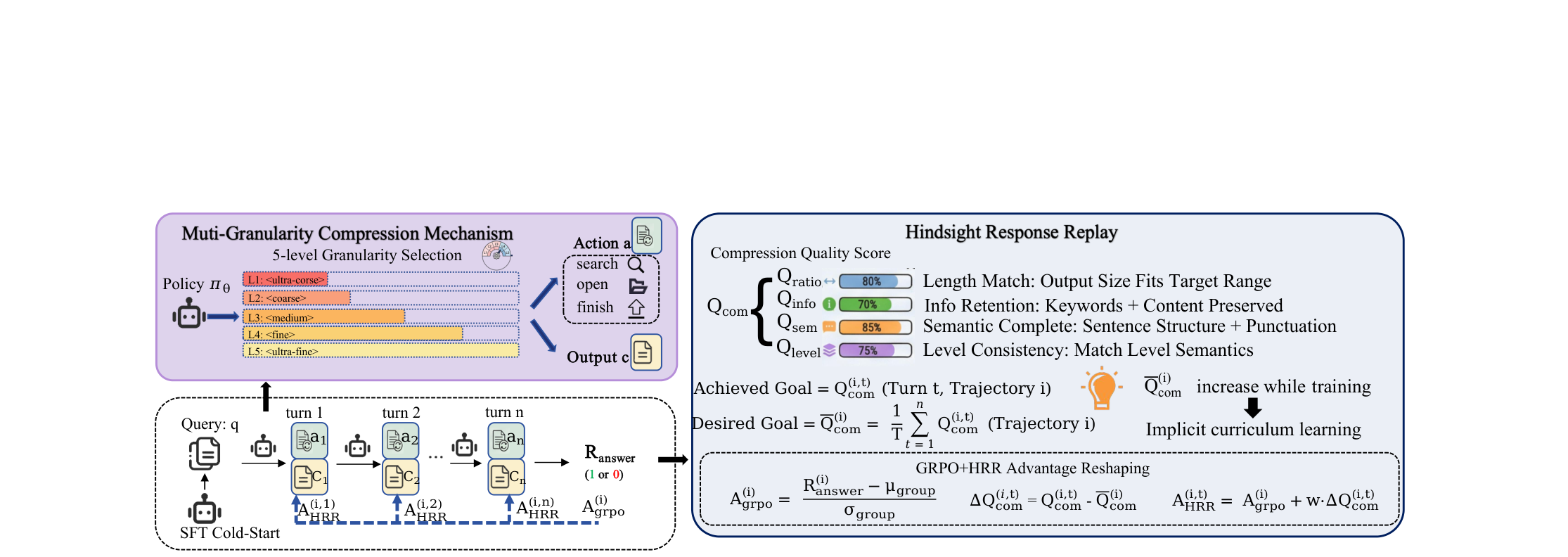
ZipRL: Adaptive Multi-Turn Context Compression with Hindsight Response Replay
Zhexin Hu, Li Wang, Xiaohan Wang, Jiajun Chai, Xiaojun Guo, Wei Lin, Xin Zhou, Guojun Yin#
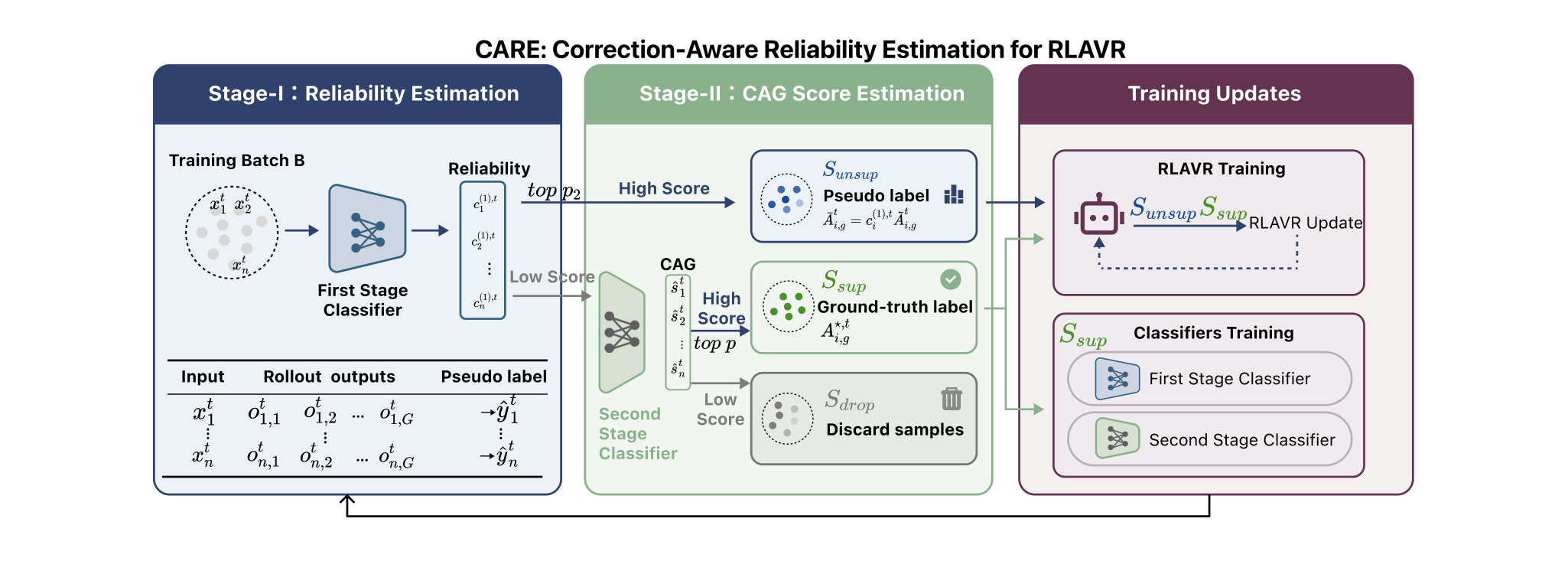
When Self-Belief Misleads: Active Label Acquisition for Reinforcement Learning with Verifiable Rewards
Li Wang*, Xiaodong Lu*, Xiaohan Wang, Yikun Ban, Jiajun Chai, Wei Lin, Tianhao Peng, Guojun Yin#
AMR-SD: Asymmetric Meta-Reflective Self-Distillation for Token-Level Credit Assignment
Zhenlin Wei*, Pu Jian*, Yingzhuo Deng*, Xiaohan Wang, Jiajun Chai, Zhexin Hu, Wei Lin, Shanbin Zhang, Guojun Yin
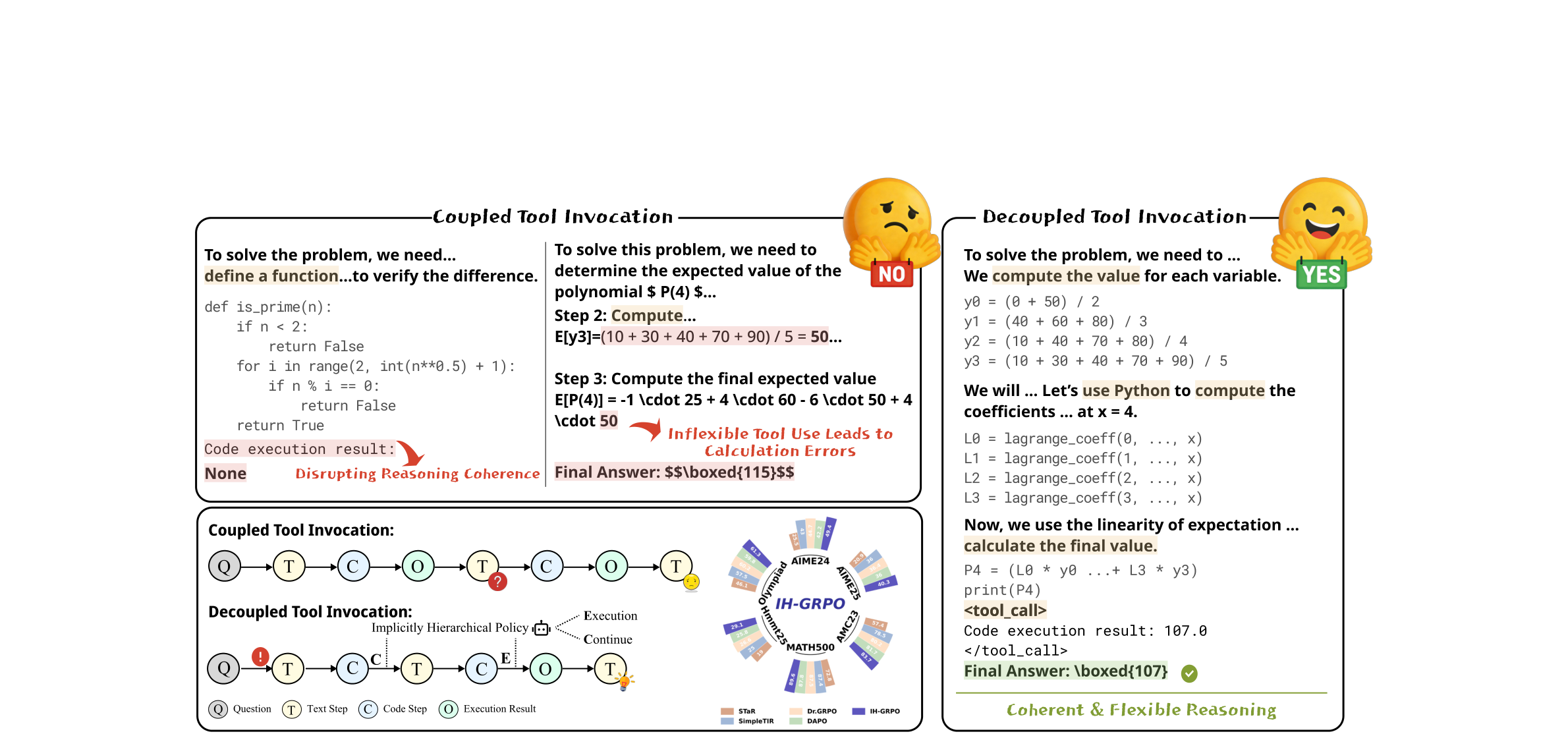
Implicit Hierarchical GRPO: Decoupling Tool Invocation from Execution for Tool-Integrated Mathematical Reasoning
Li Wang*, Xiaohan Wang*, Xiaodong Lu, Zipeng Zhang, Jinyang Wu, Jiajun Chai, Wei Lin, Guojun Yin#
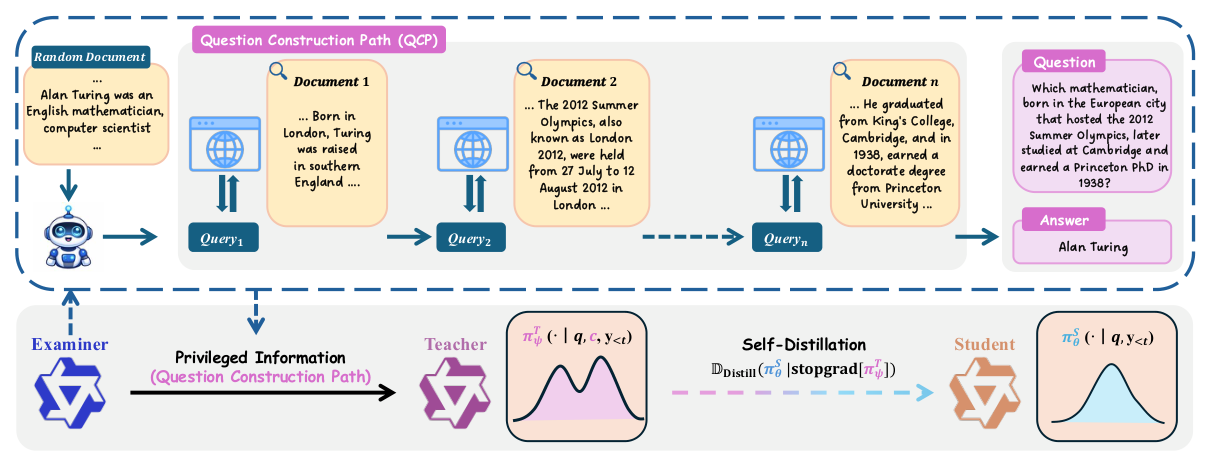
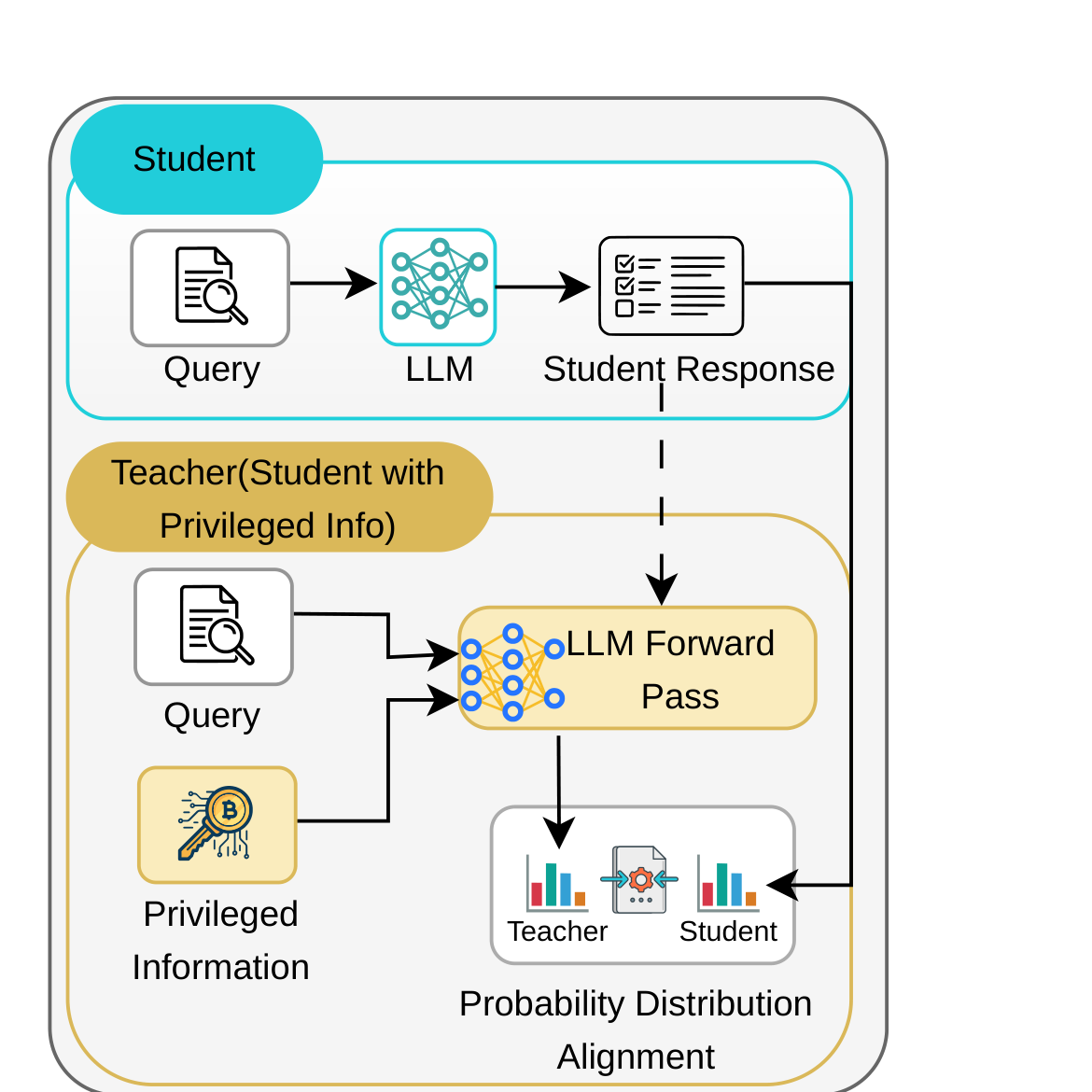
π-Play: Multi-Agent Self-Play via Privileged Self-Distillation without External Data
Yaocheng Zhang*, Yuanheng Zhu*, Wenyue Chong, Songjun Tu, Qichao Zhang, Jiajun Chai, Xiaohan Wang, Wei Lin, Guojun Yin, Dongbin Zhao
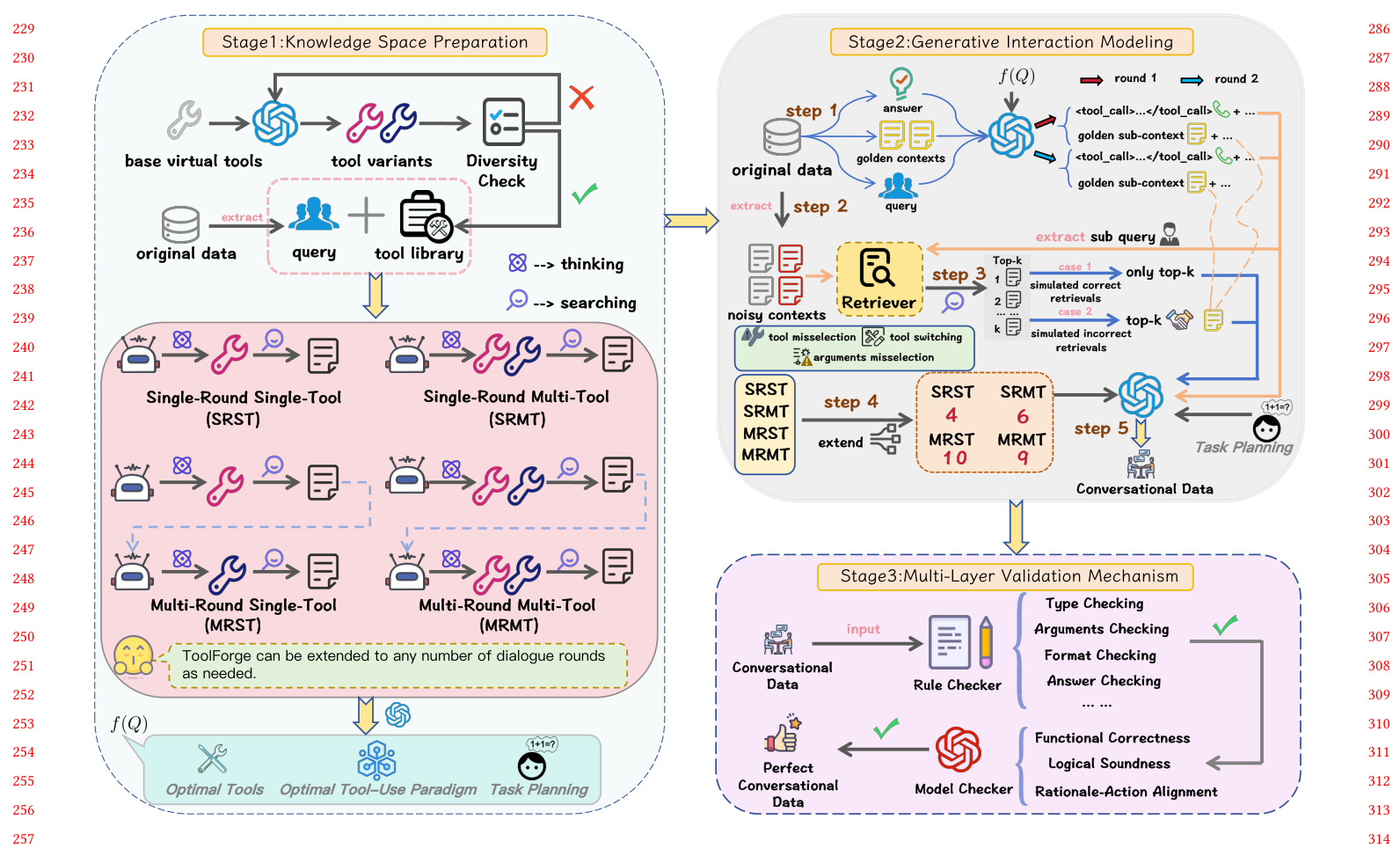
ToolForge: A Data Synthesis Pipeline for Multi-Hop Search without Real-World APIs
Hao Chen, Zihao Hu, Jiajun Chai, Hexiong Yang, Hang He, Xiaohan Wang, Wei Lin, Lei Wang, Guojun Yin#
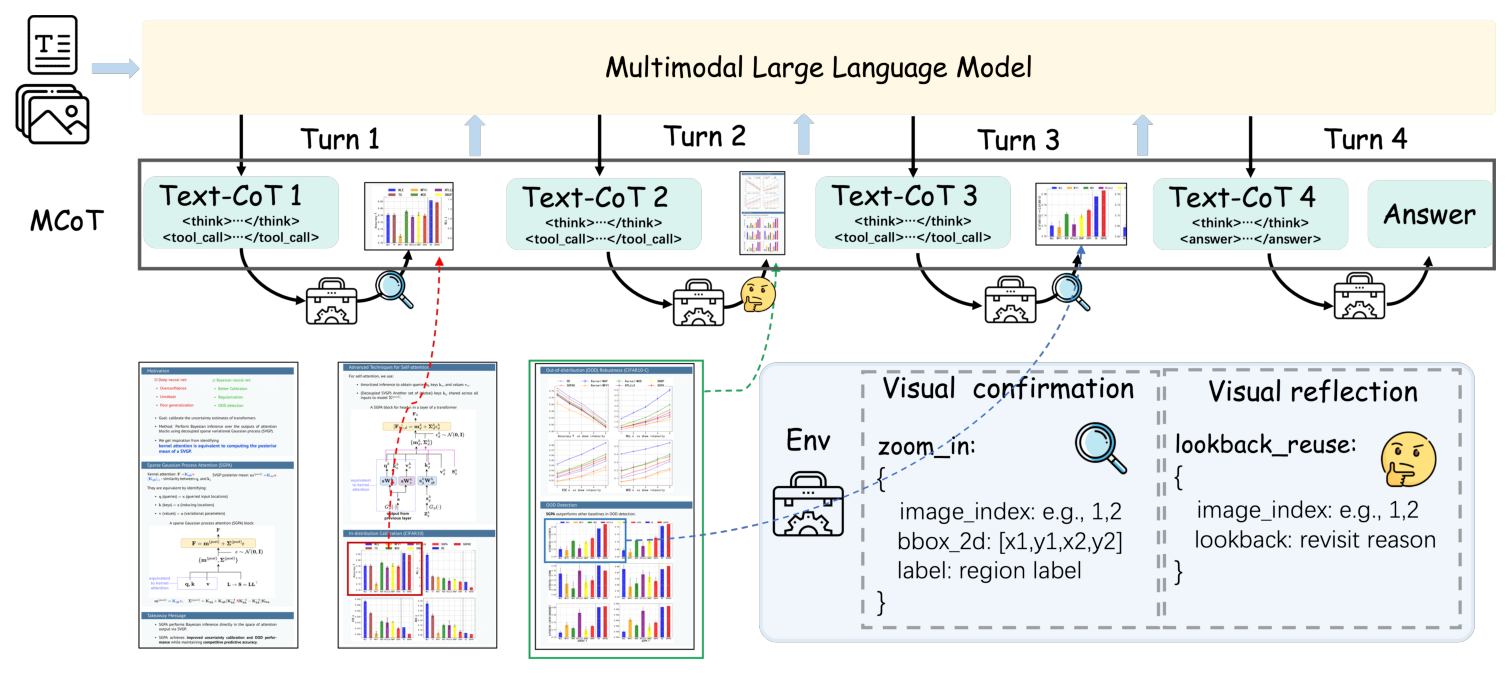
IMAgent: Training Multi-Image Vision Agents via End2End Reinforcement Learning
Chengqi Dong, Chuhuai Yue, Hang He, Rongge Mao, Fenghe Tang, S Kevin Zhou, Zekun Xu, Xiaohan Wang, Jiajun Chai, Guojun Yin#
Published Papers
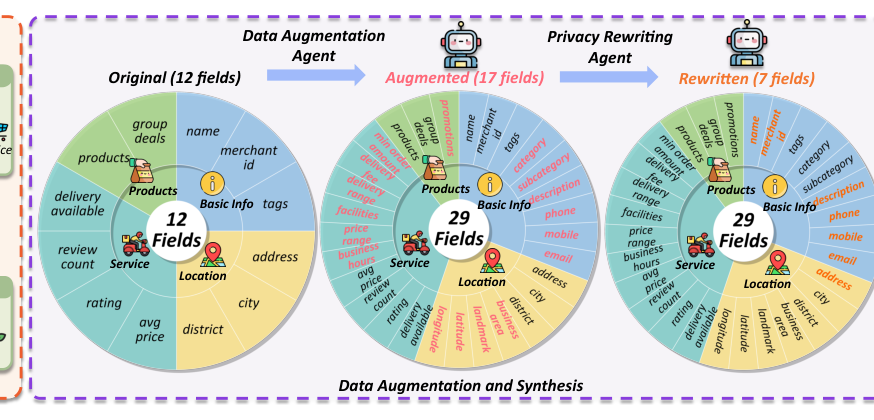
LocalSearchBench: Benchmarking Agentic Search in Real-World Local Life Services
Hang He, Chuhuai Yue, Chengqi Dong, Mingxue Tian, Hao Chen, Zhenfeng Liu, Jiajun Chai*, Xiaohan Wang, Yufei Zhang, Qun Liao, Guojun Yin#, Wei Lin, Chengcheng Wan, Haiying Sun, Ting Su
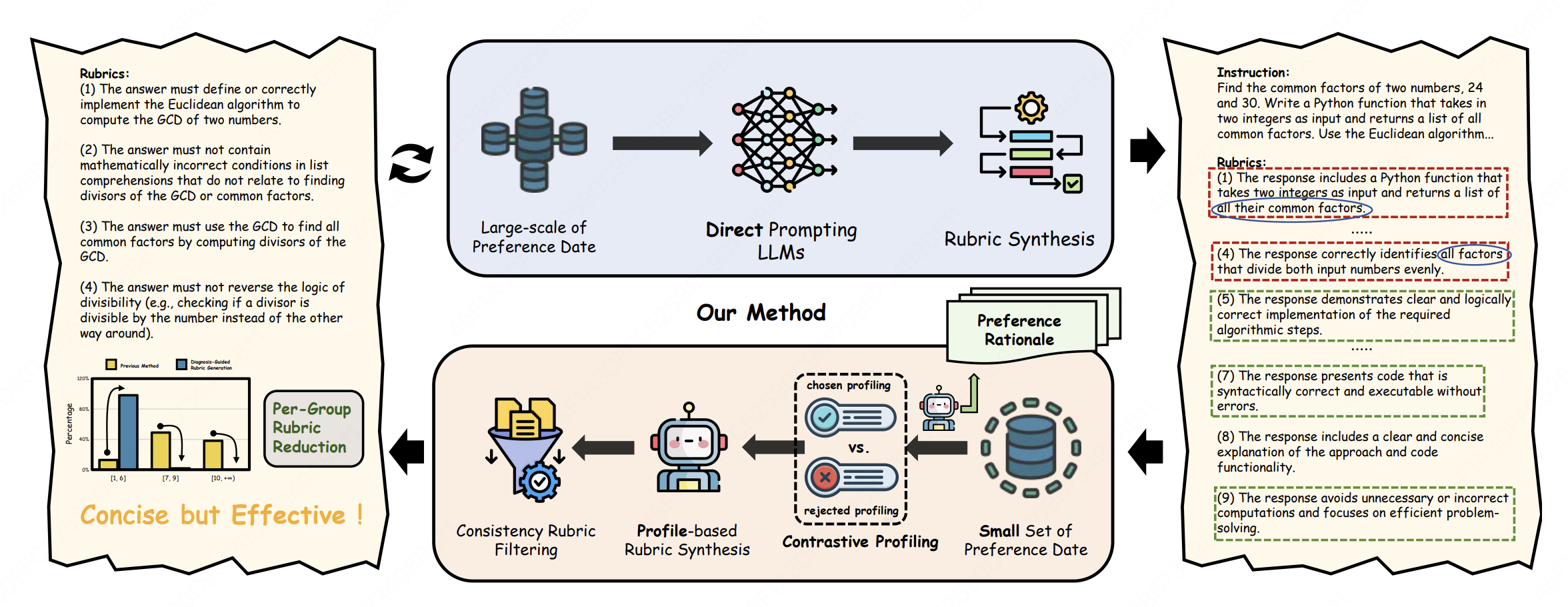
CDRRM: Contrast-Driven Rubric Generation for Reliable and Interpretable Reward Modeling
Dengcan Liu*, Fengkai Yang*, Xiaohan Wang, Shuai Yan, Jiajun Chai, Jianxin Li, Yikun Ban, Zhichao Mao, Wei Lin, Guojun Yin#
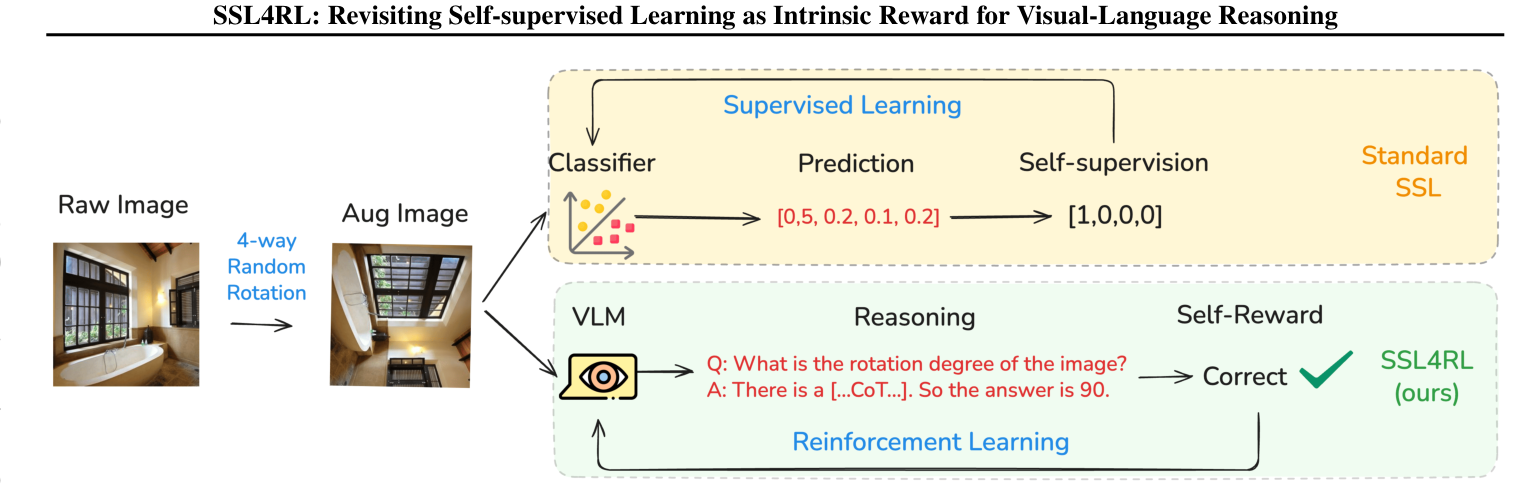
SSL4RL: Revisiting Self-supervised Learning as Intrinsic Reward for Visual-Language Reasoning
Xiaojun Guo*, Runyu Zhou*, Yifei Wang, Qi Zhang, Chenheng Zhang, Stefanie Jegelka, Xiaohan Wang, Jiajun Chai, Guojun Yin, Wei Lin, Yisen Wang
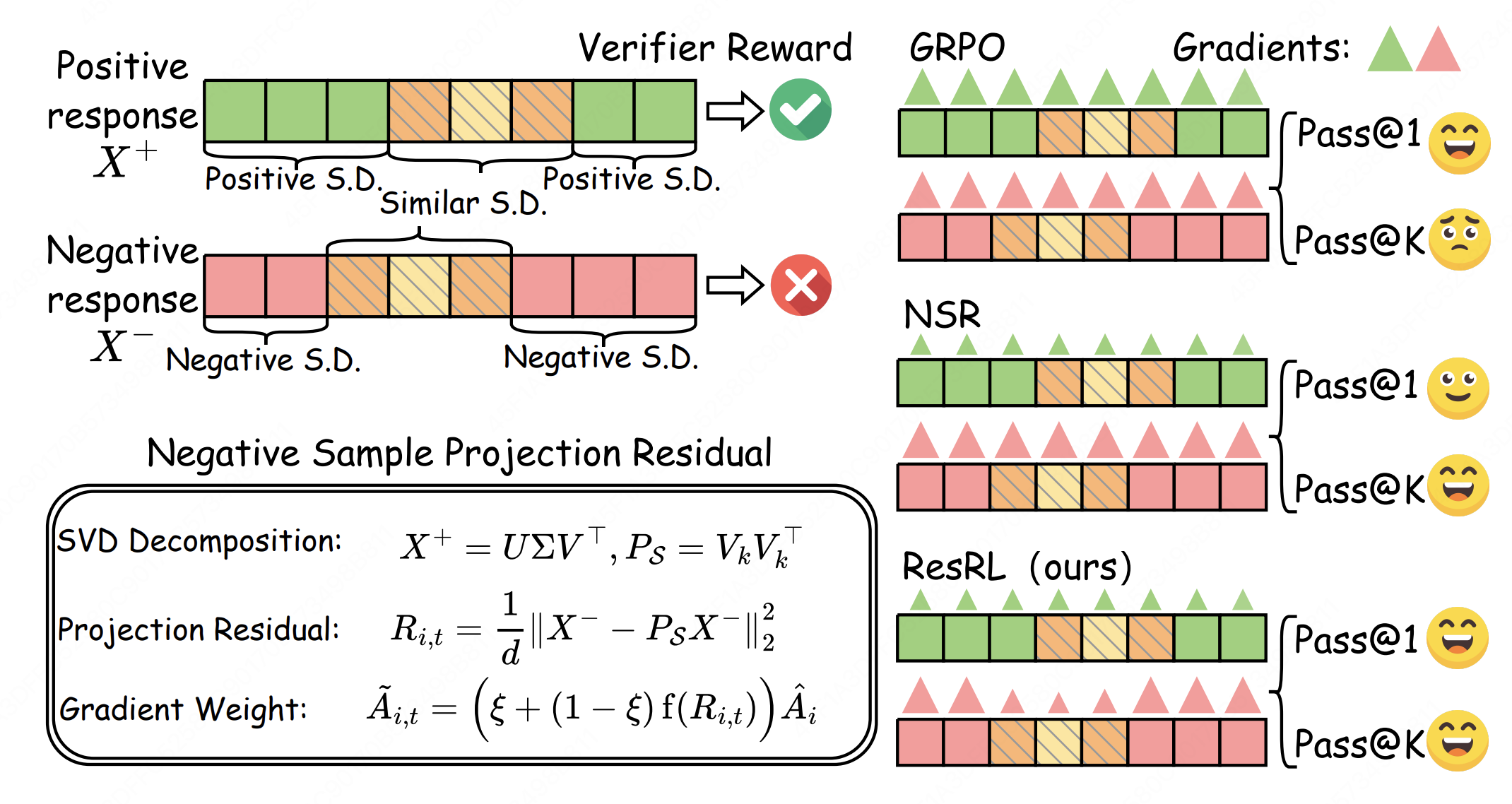
ResRL: Boosting LLM Reasoning via Negative Sample Projection Residual Reinforcement Learning
Zihan Lin*, Xiaohan Wang*, Jie Cao, Jiajun Chai, Li Wang, Xiaodong Lu, Wei Lin, Ran He, Guojun Yin#
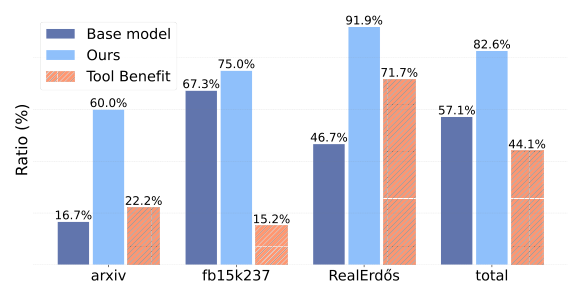
GRASP: Graph Reasoning via Agentic Solving and Probing of LLMs
Xiaojun Guo*, Mingxue Tian*, Chenheng Zhang, Xiaohan Wang, Jiajun Chai, Guojun Yin, Wei Lin, Yifei Wang, Yisen Wang
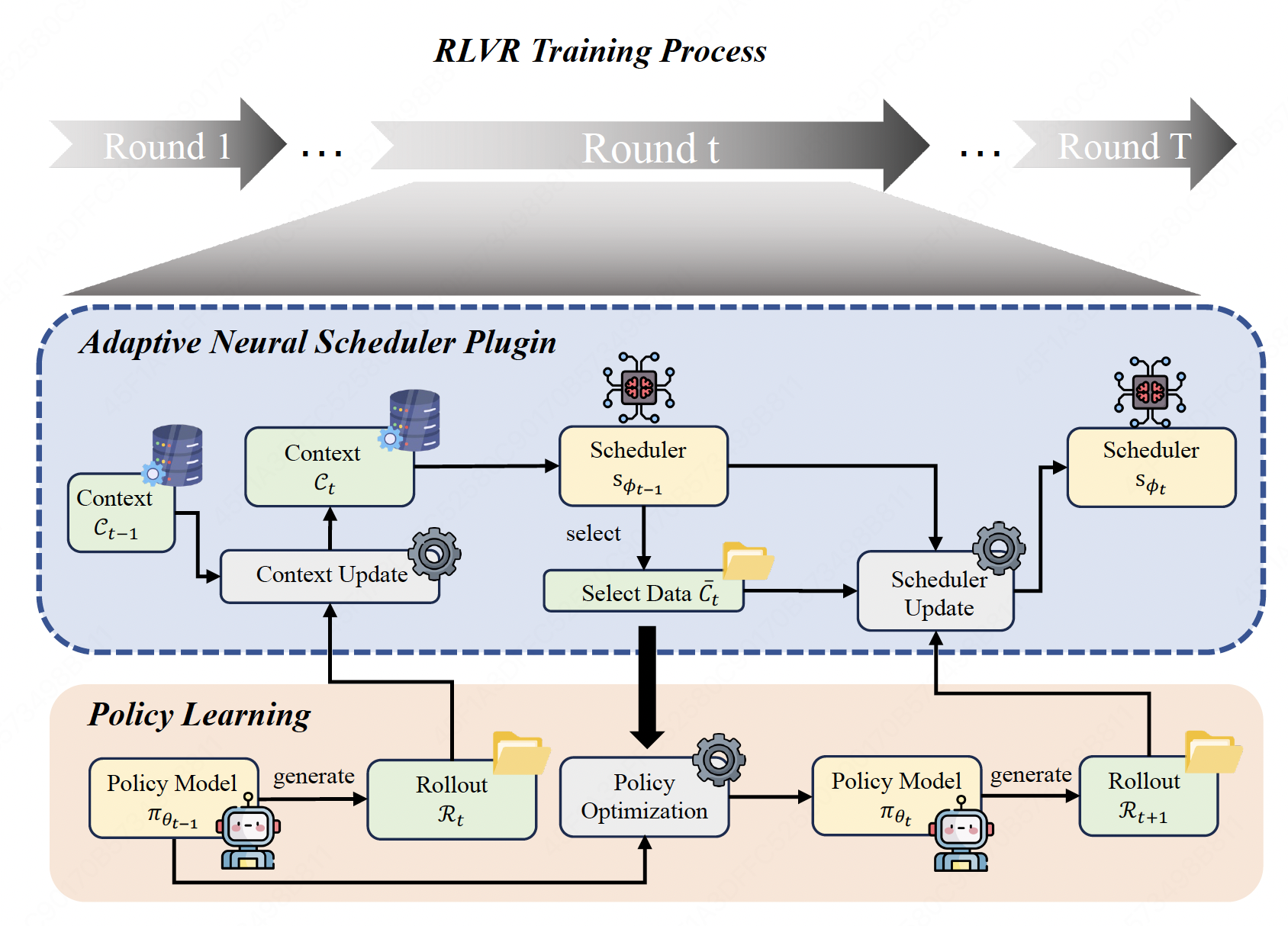
Contextual Rollout Bandits for Reinforcement Learning with Verifiable Rewards
Xiaodong Lu, Xiaohan Wang, Jiajun Chai, Guojun Yin, Wei Lin, Zhijun Chen, Yu Luo, Fuzhen Zhuang, Yikun Ban, Deqing Wang

Rethinking Personalization in Large Language Models at the Token Level
Chenheng Zhang, Yijun Lu, Lizhe Fang, Chunyuan Zheng, Jiajun Chai, Xiaohan Wang, Guojun Yin, Wei Lin, Yisen Wang, Zhouchen Lin
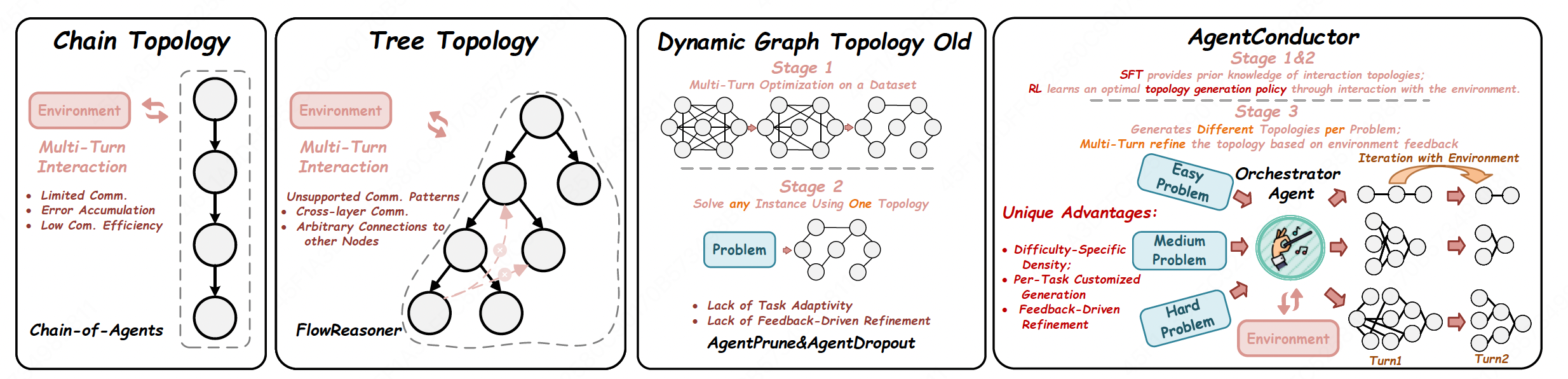
AgentConductor: Topology Evolution for Multi-Agent Competition-Level Code Generation
Siyu Wang, Ruotian Lu, Zhihao Yang, Yuchao Wang, Yanzhou Zhang, Lei Xu, Qimin Xu, Guojun Yin, Cailian Chen, Xinping Guan
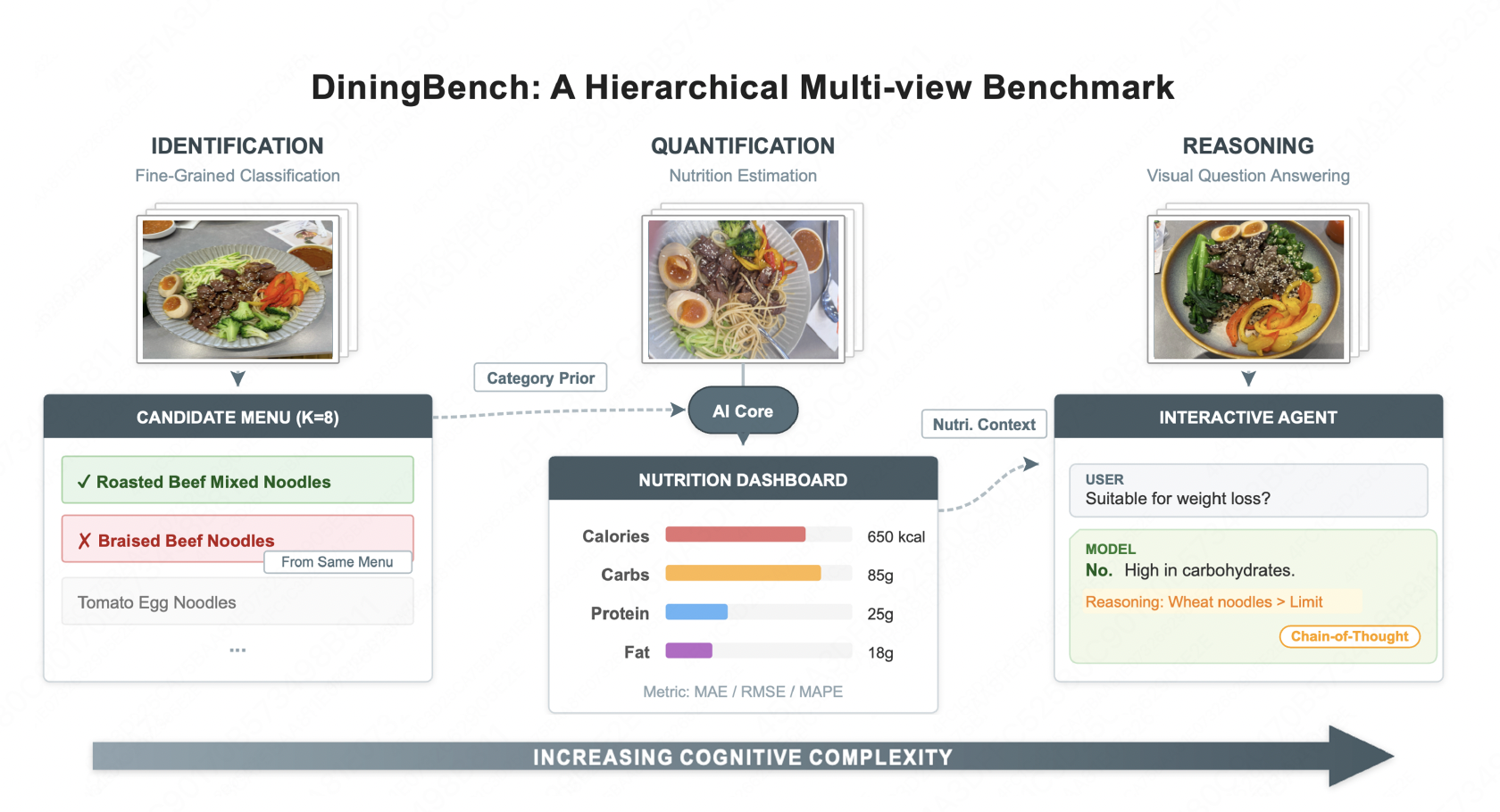
DiningBench: A Hierarchical Multi-view Benchmark for Perception and Reasoning in the Dietary Domain
Song Jin*, Juntian Zhang*, Xun Zhang, Zeying Tian, Fei Jiang, Guojun Yin, Wei Lin, Yong Liu, Rui Yan
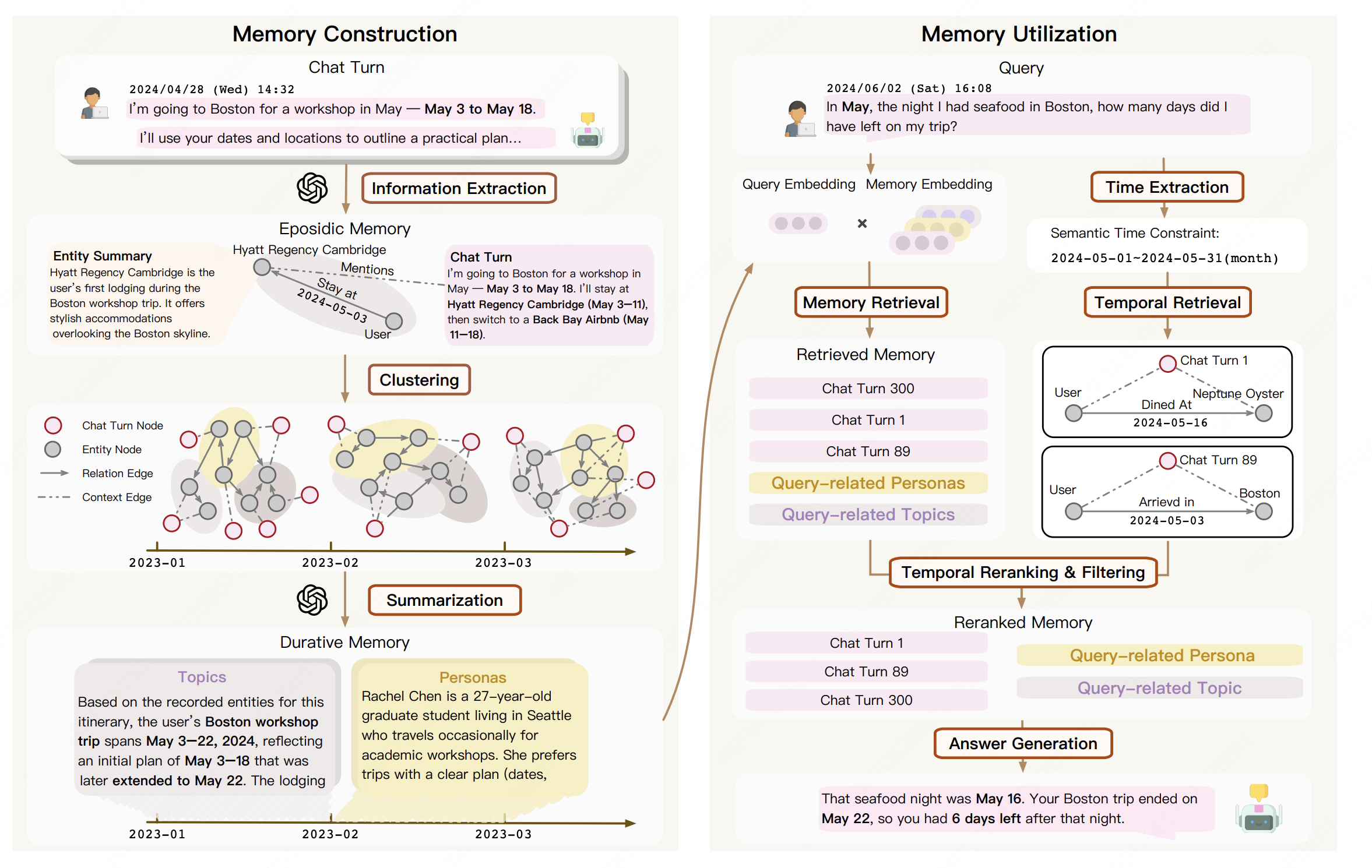
Beyond Dialogue Time: Temporal Semantic Memory for Personalized LLM Agents
Miao Su, Yucan Guo, Zhongni Hou, Long Bai, Zixuan Li, Yufei Zhang, Guojun Yin, Wei Lin, Xiaolong Jin, Jiafeng Guo, Xueqi Cheng
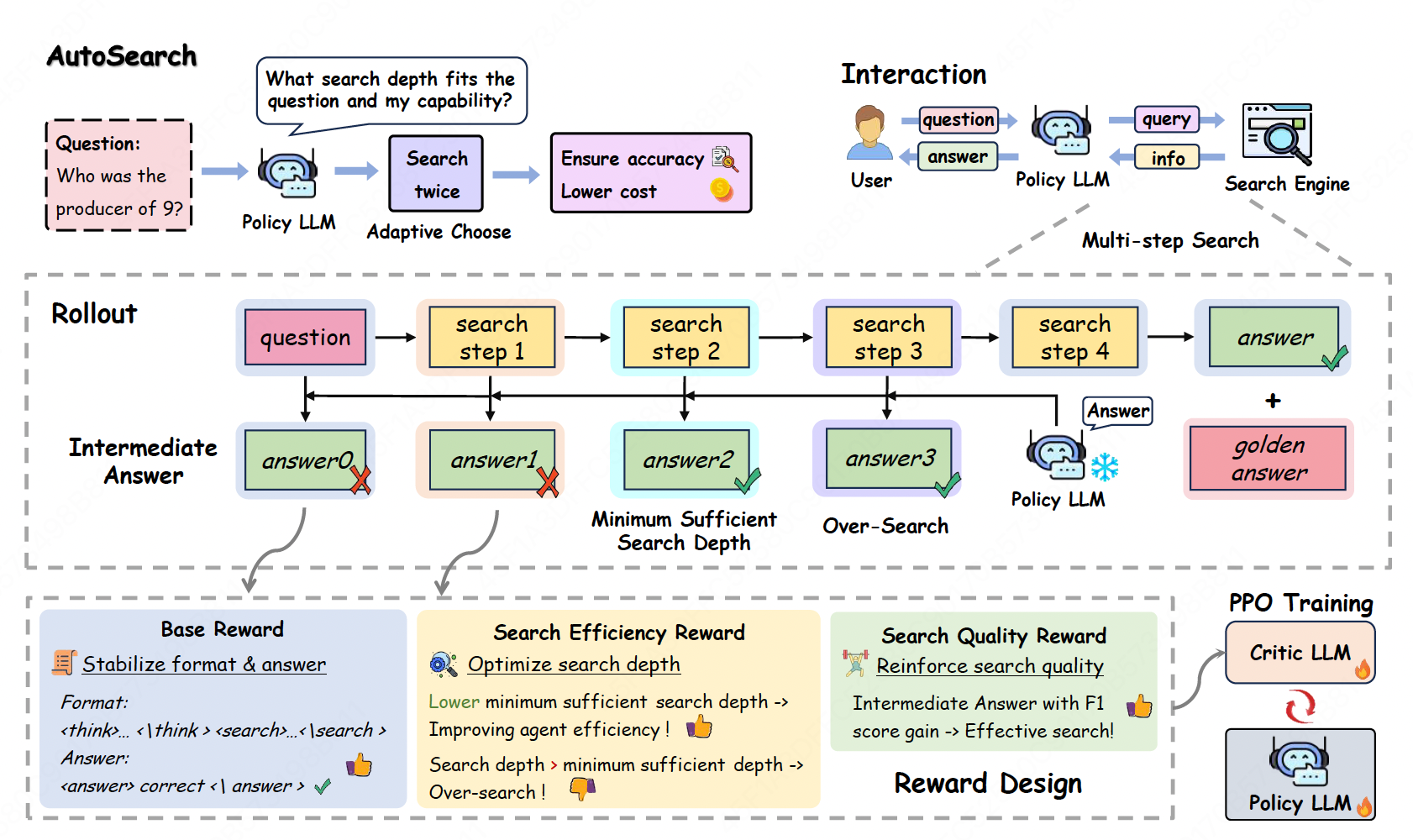
AutoSearch: Adaptive Search Depth for Efficient Agentic RAG via Reinforcement Learning
Jingbo Sun*, Wenyue Chong*, Songjun Tu, Qichao Zhang, Yaocheng Zhang, Jiajun Chai, Xiaohan Wang, Wei Lin, Guojun Yin, Dongbin Zhao
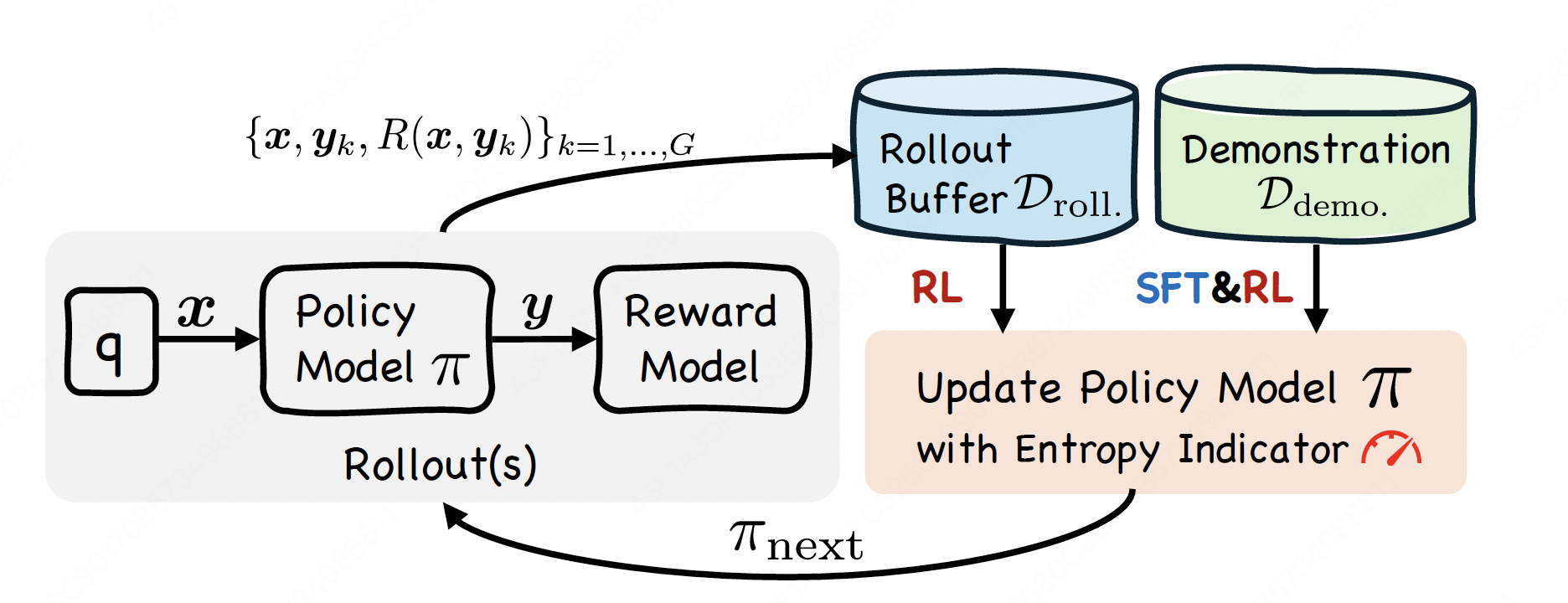
SRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning
Yuqian Fu*, Tinghong Chen*, Jiajun Chai, Xihuai Wang, Songjun Tu, Guojun Yin, Wei Lin, Qichao Zhang, Yuanheng Zhu, Dongbin Zhao
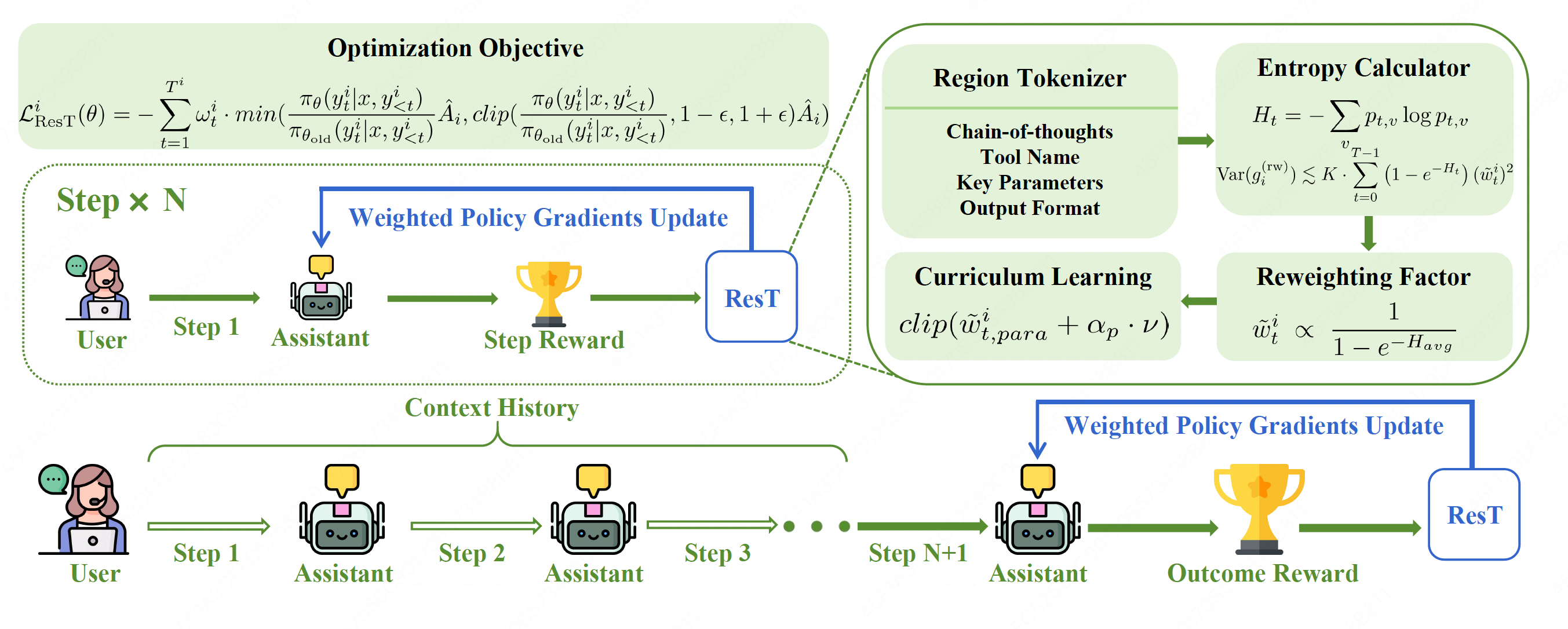
ResT: Reshaping Token-Level Policy Gradients for Tool-Use Large Language Models
Zihan Lin*, Xiaohan Wang*, Jie Cao, Jiajun Chai, Guojun Yin#, Wei Lin, Ran He

SAE as a Crystal Ball: Interpretable Features Predict Cross-domain Transferability of LLMs without Training
Qi Zhang*, Yifei Wang*, Xiaohan Wang, Jiajun Chai, Guojun Yin, Wei Lin, Yisen Wang
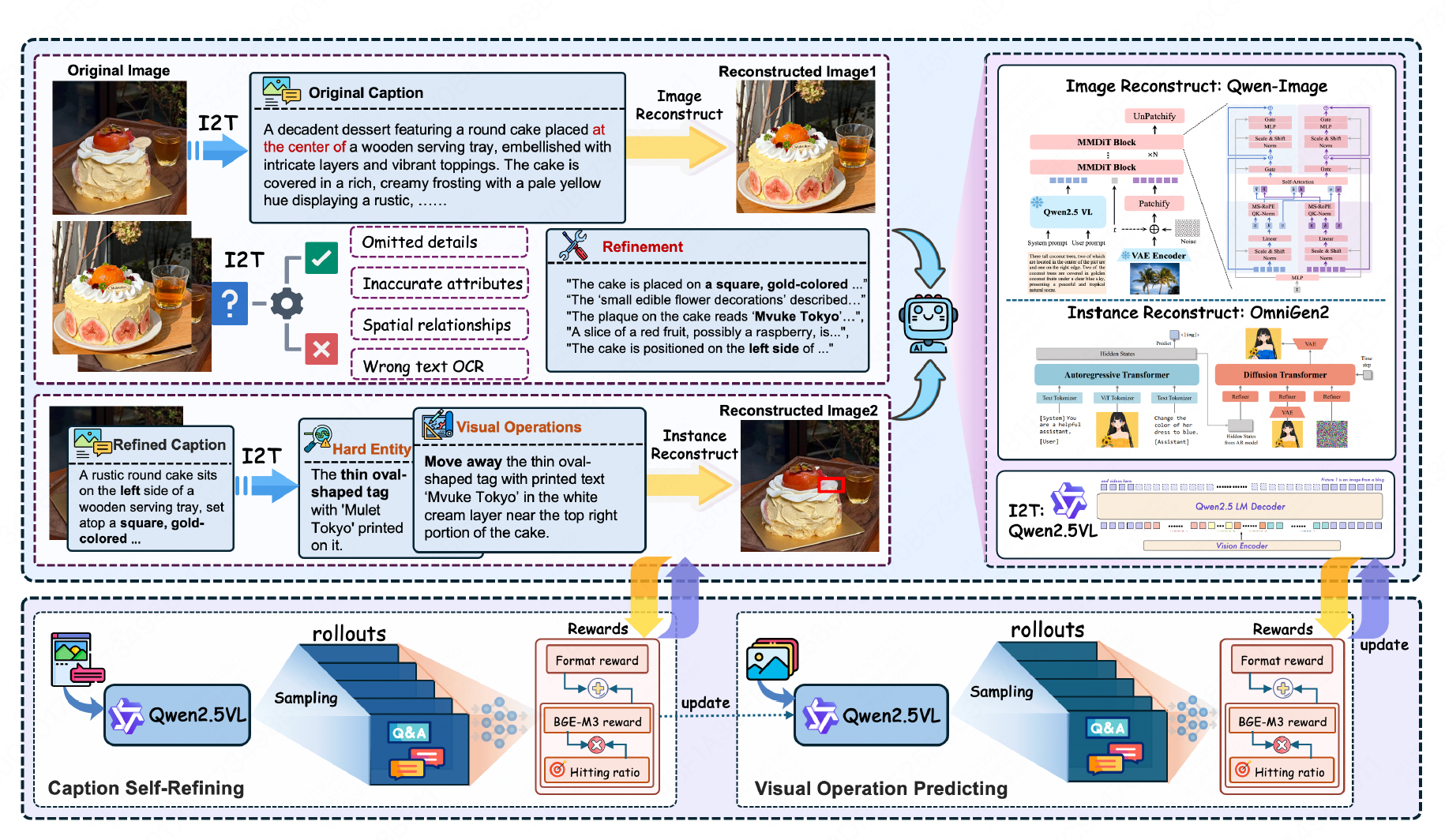
ViPER: Empowering the Self-Evolution of Visual Perception Abilities in Vision-Language Model
Juntian Zhang, Song Jin, Chuanqi Cheng, Yuhan Liu, Yankai Lin, Xun Zhang, Yufei Zhang, Fei Jiang, Guojun Yin, Wei Lin, Rui Yan
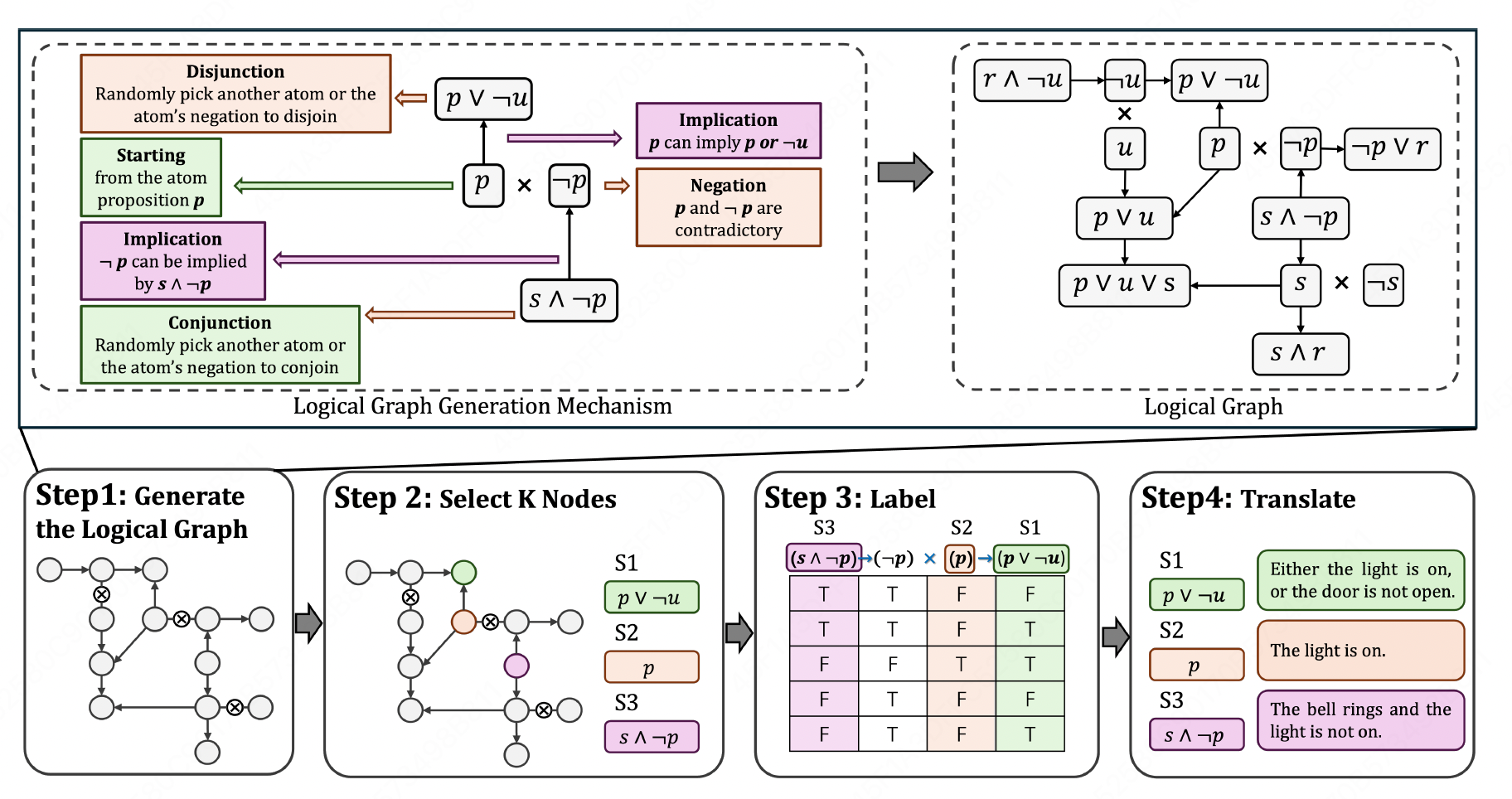
LogiConBench: Benchmarking Logical Consistencies of LLMs
Zheng Chen, Chuan Zhou, Fengxiang Cheng, Yip Tin Po, Fenrong Liu, Yisen Wang, Jiajun Chai, Xiaohan Wang, Guojun Yin, Wei Lin, Bo Li, Haoxuan Li, Zhouchen Lin
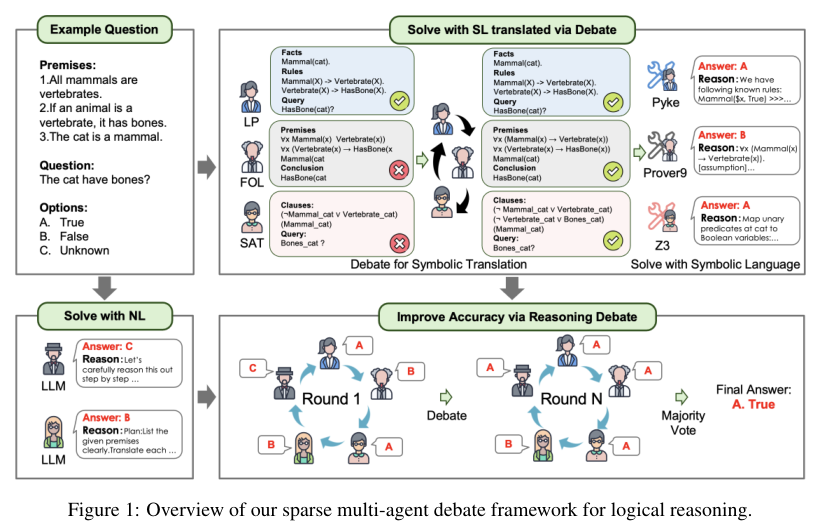
MAD-Logic: Multi-Agent Debate Enhances Symbolic Translation and Reasoning
Haocheng Yang, Fengxiang Cheng, Tianjun Yao, Mengyue Yang, Jiajun Chai, Xiaohan Wang, Guojun Yin, Wei Lin, Soummya Kar, Fenrong Liu*, Haoxuan Li*, Yisen Wang*
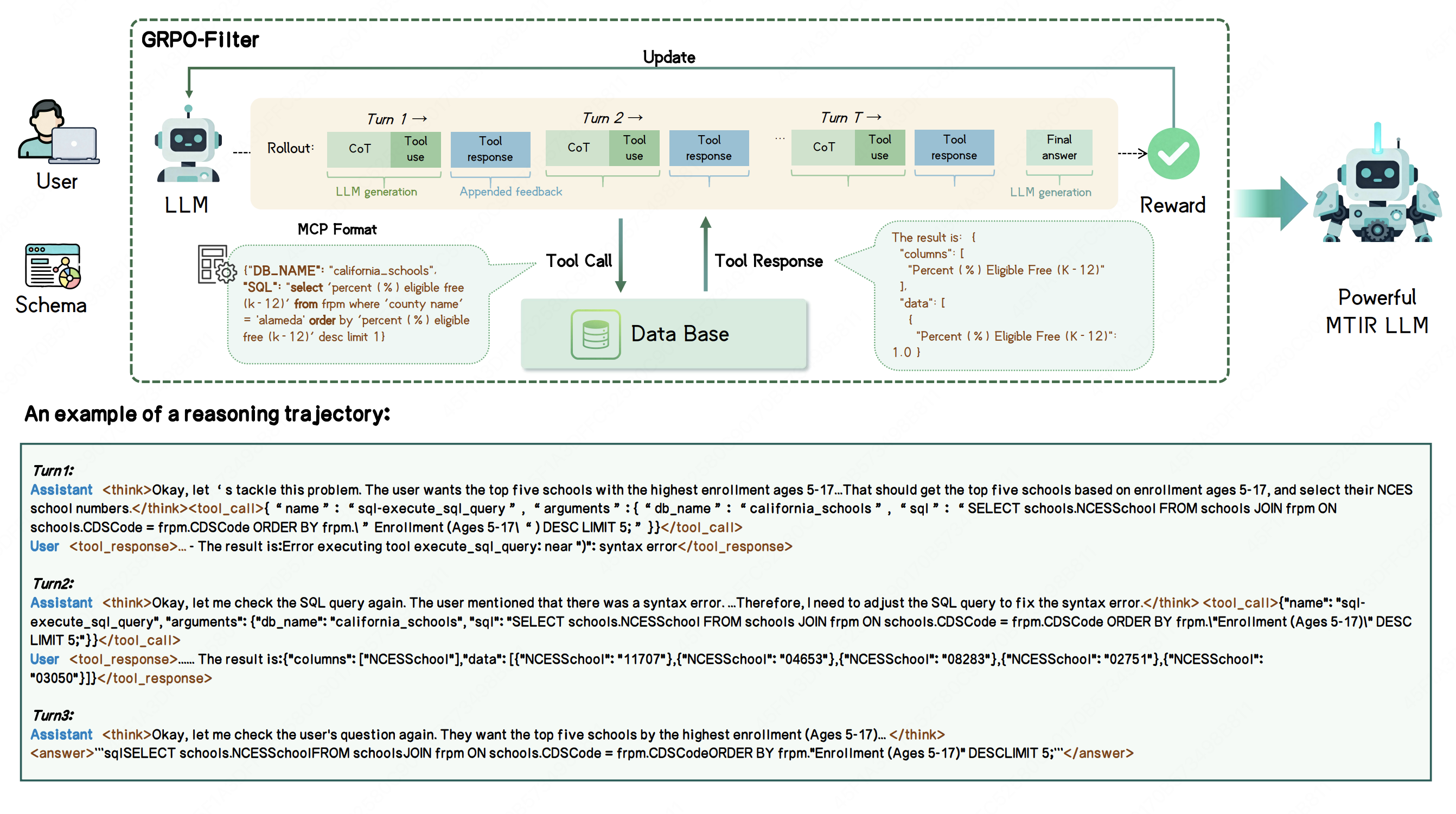
MTIR-SQL: Multi-turn Tool-Integrated Reasoning Reinforcement Learning for Text-to-SQL
Zekun Xu*, Siyu Xia*, Chuhuai Yue, Jiajun Chai, Mingxue Tian, Xiaohan Wang, Wei Lin, Haoxuan Li, Guojun Yin#
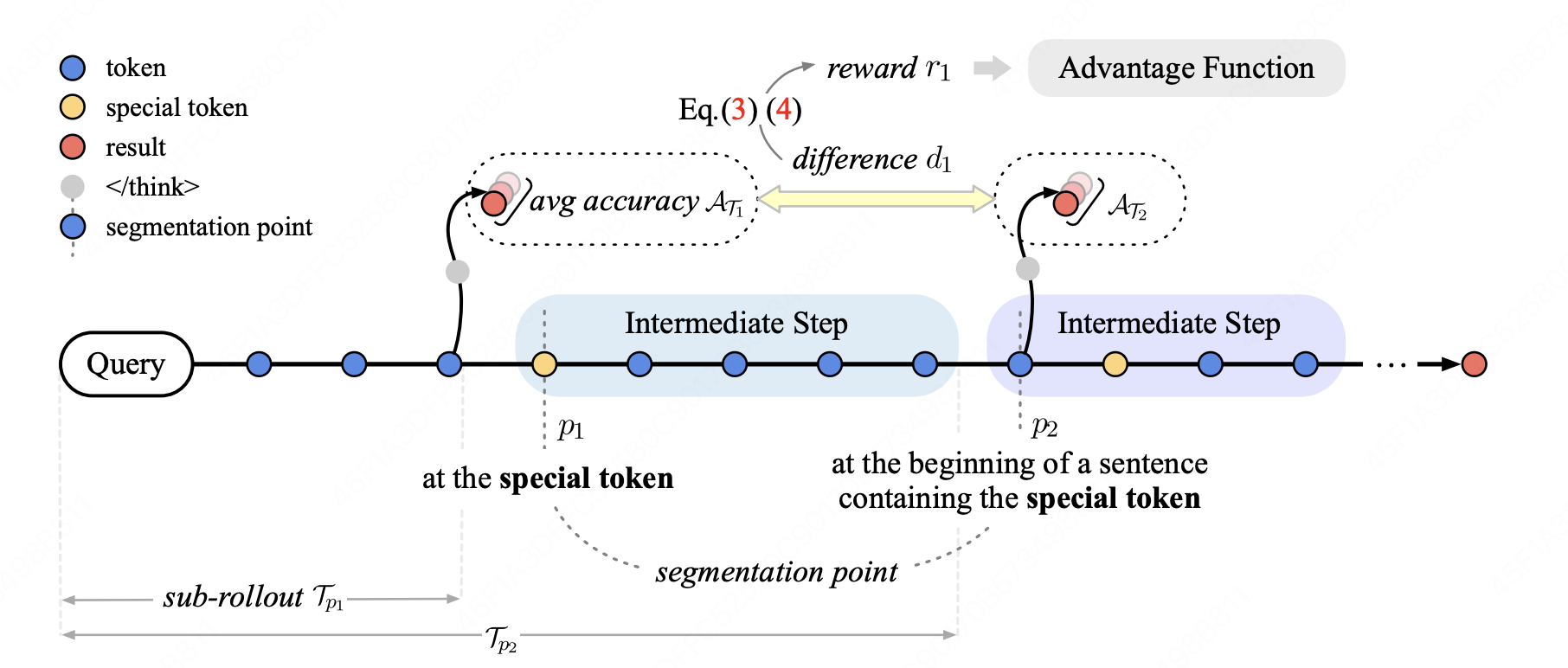
Promoting Efficient Reasoning with Verifiable Stepwise Reward
Chuhuai Yue, Chengqi Dong, Yinan Gao, Hang He, Jiajun Chai, Guojun Yin#, Wei Lin
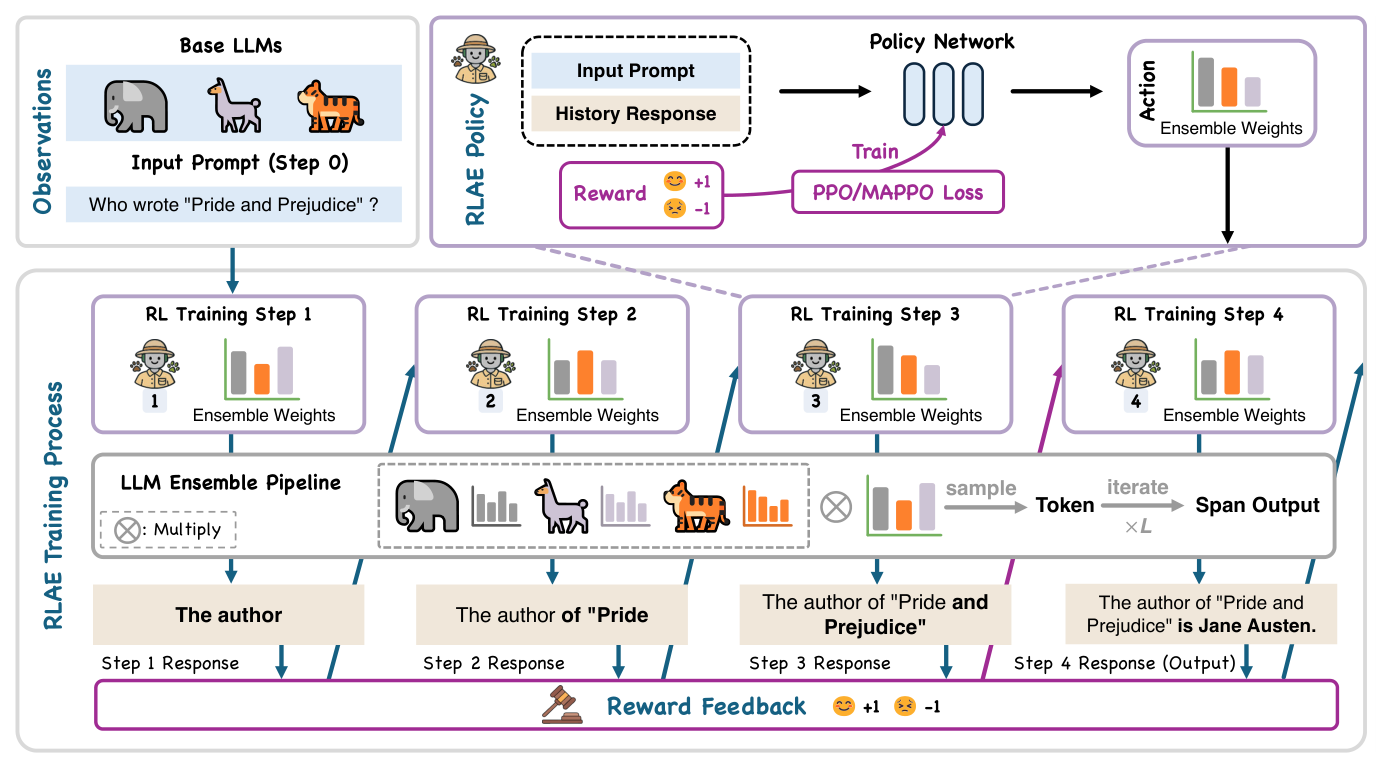
RLAE: Reinforcement Learning-Assisted Ensemble for LLMs
Yuqian Fu, Yuanheng Zhu, Jiajun Chai, Guojun Yin, Wei Lin, Qichao Zhang, Dongbin Zhao
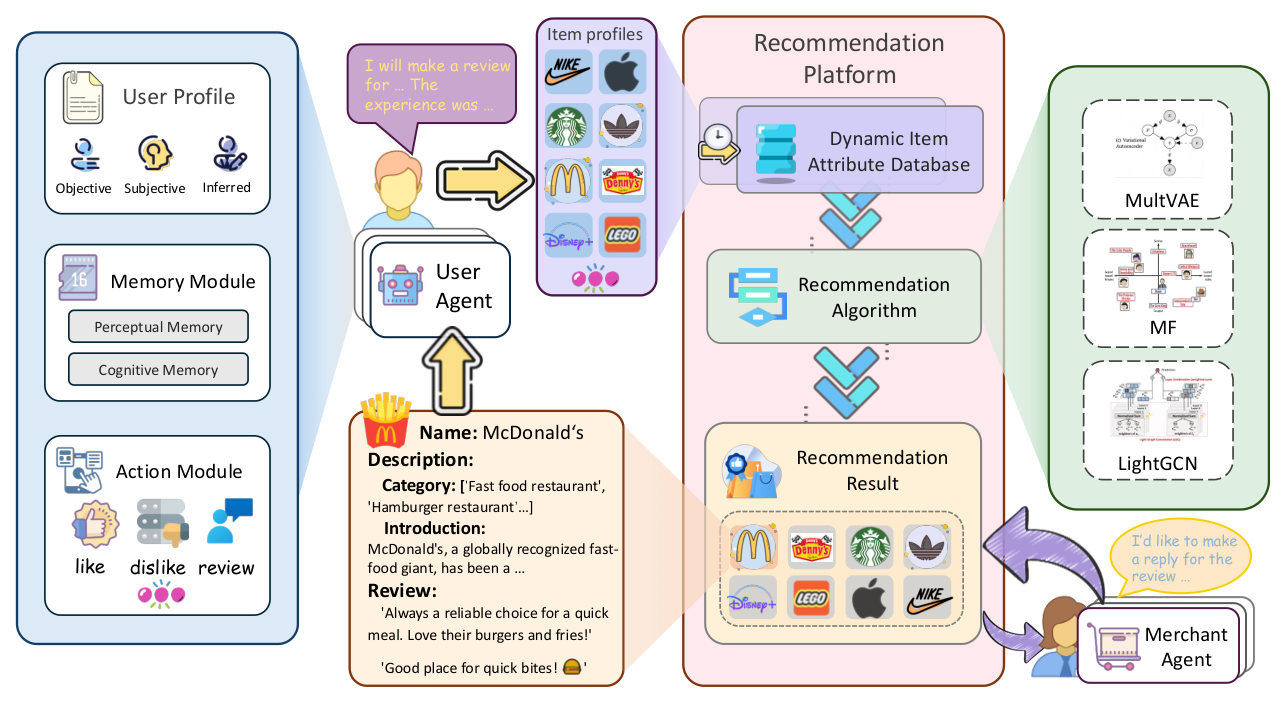
Beyond Static Testbeds: An Interaction-Centric Agent Simulation Platform for Dynamic Recommender Systems
Song Jin*, Juntian Zhang*, Yuhan Liu, Xun Zhang, Yufei Zhang, Guojun Yin, Fei Jiang, Wei Lin, Rui Yan
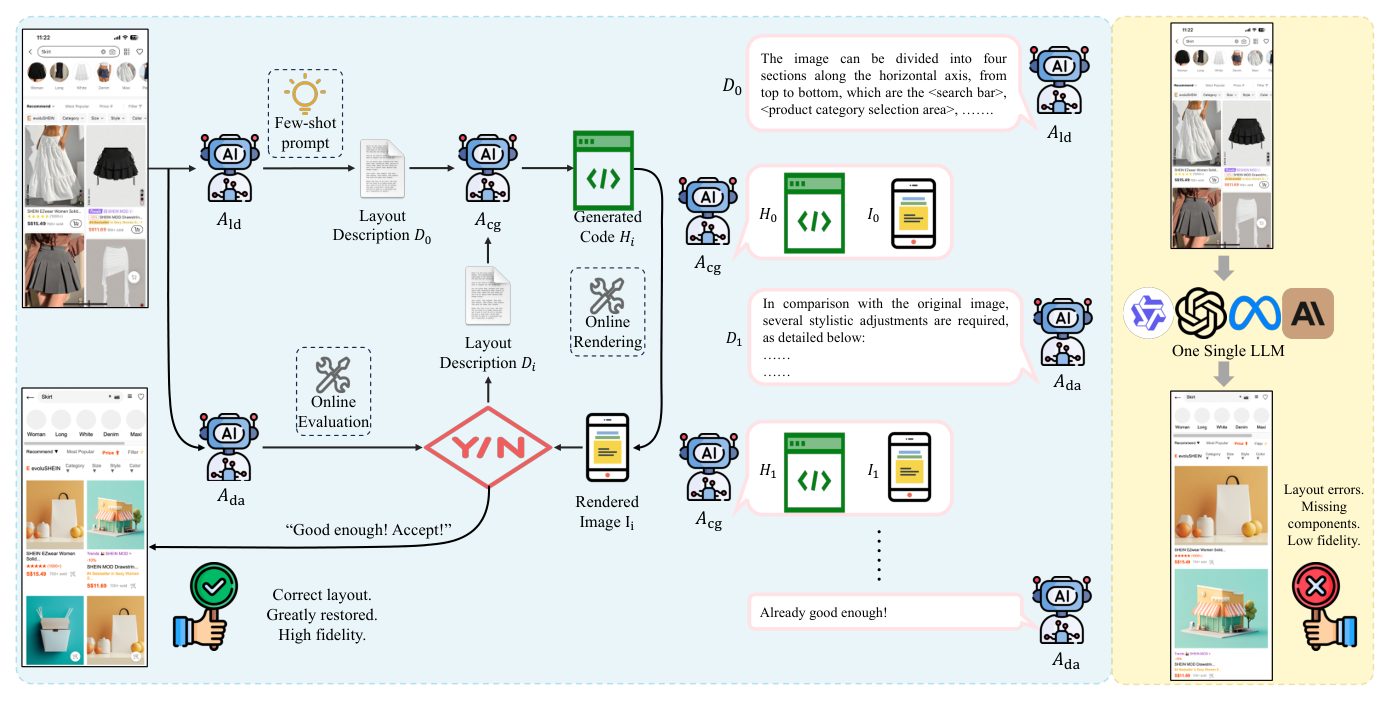
UIOrchestra: Generating High-Fidelity Code from UI Designs with a Multi-agent System
Chuhuai Yue, Jiajun Chai, Yufei Zhang, Zixiang Ding, Xihao Liang, Peixin Wang, Shihai Chen, Wang Yixuan, Yanping Wang, Guojun Yin, Wei Lin
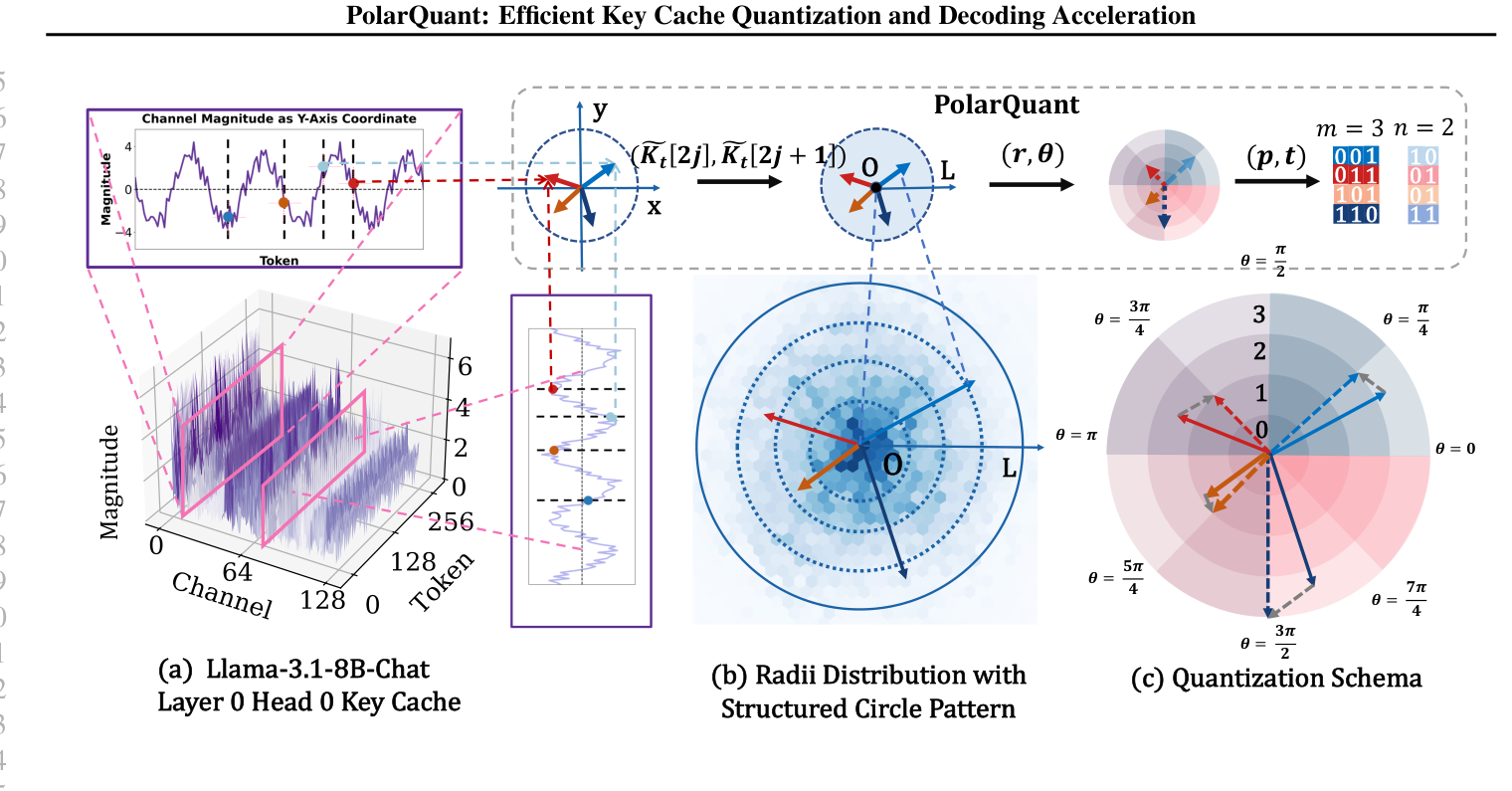
PolarQuant: Leveraging Polar Transformation for Efficient Key Cache Quantization and Decoding Acceleration
Songhao Wu*, Ang Lv*, Xiao Feng, Yufei Zhang, Xun Zhang, Guojun Yin#, Wei Lin, Rui Yan
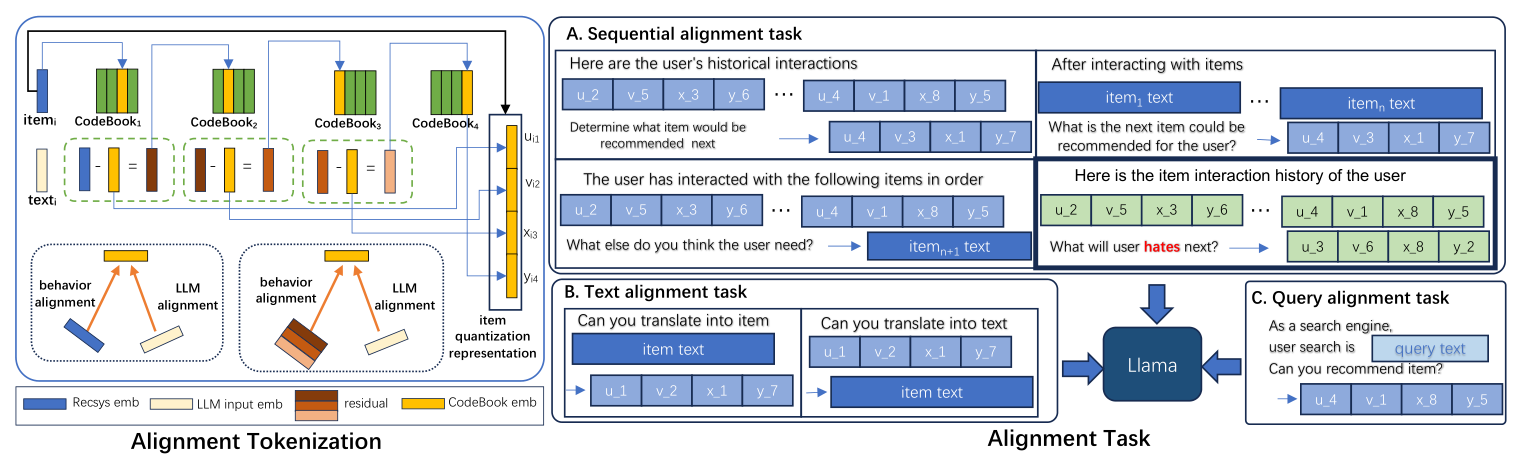
Semantic Convergence: Harmonizing Recommender Systems via Two-Stage Alignment and Behavioral Semantic Tokenization
Guanghan Li, Xun Zhang, Yufei Zhang, Yifan Yin, Guojun Yin#, Wei Lin
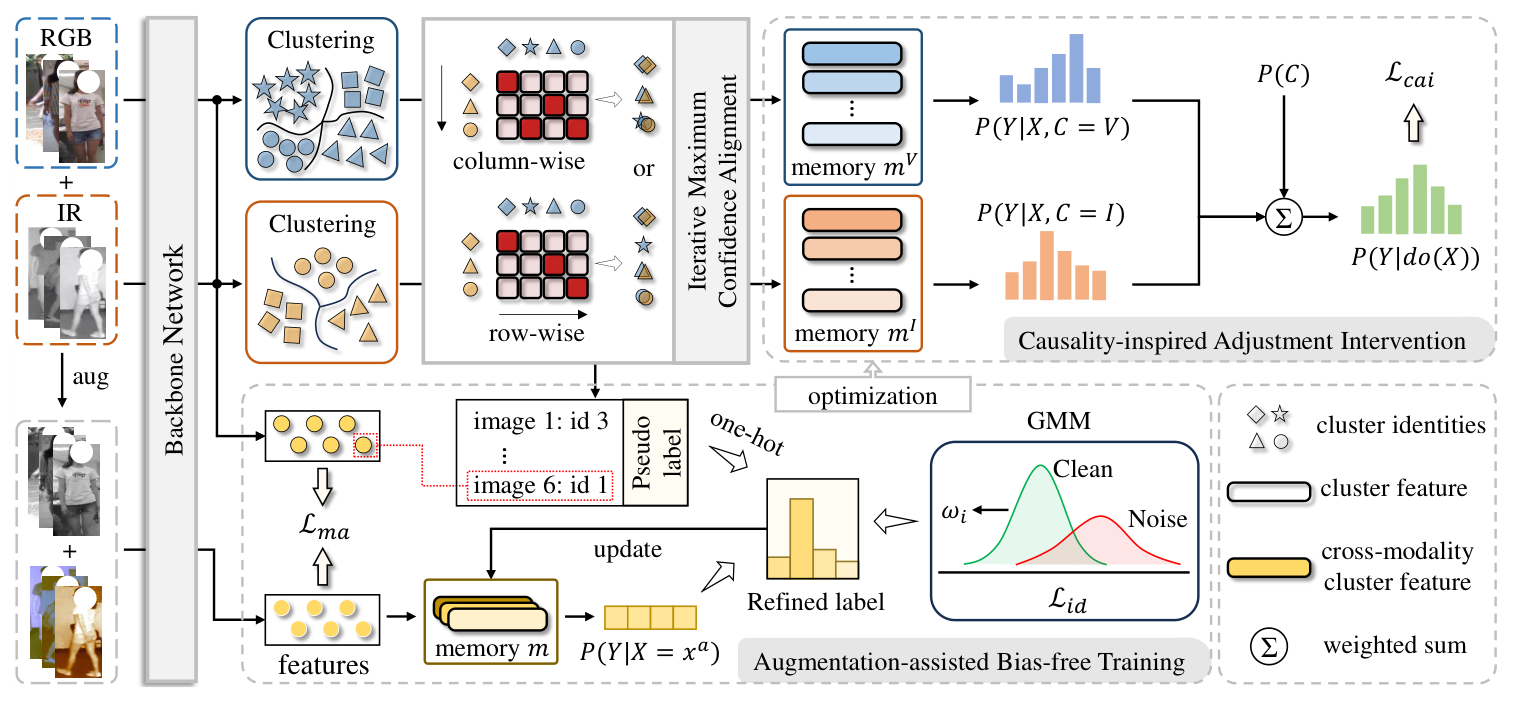
Dual-level Modality Debiasing Learning for Unsupervised Visible-Infrared Person Re-Identification
Jiaze Li, Yan Lu, Bin Liu, Guojun Yin, Mang Ye
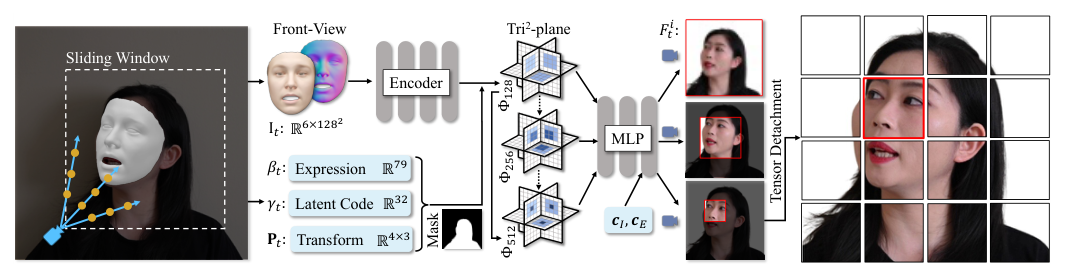
Tri2-plane: Thinking Head Avatar via Feature Pyramid
Luchuan Song, Pinxin Liu, Lele Chen, Guojun Yin, Chenliang Xu
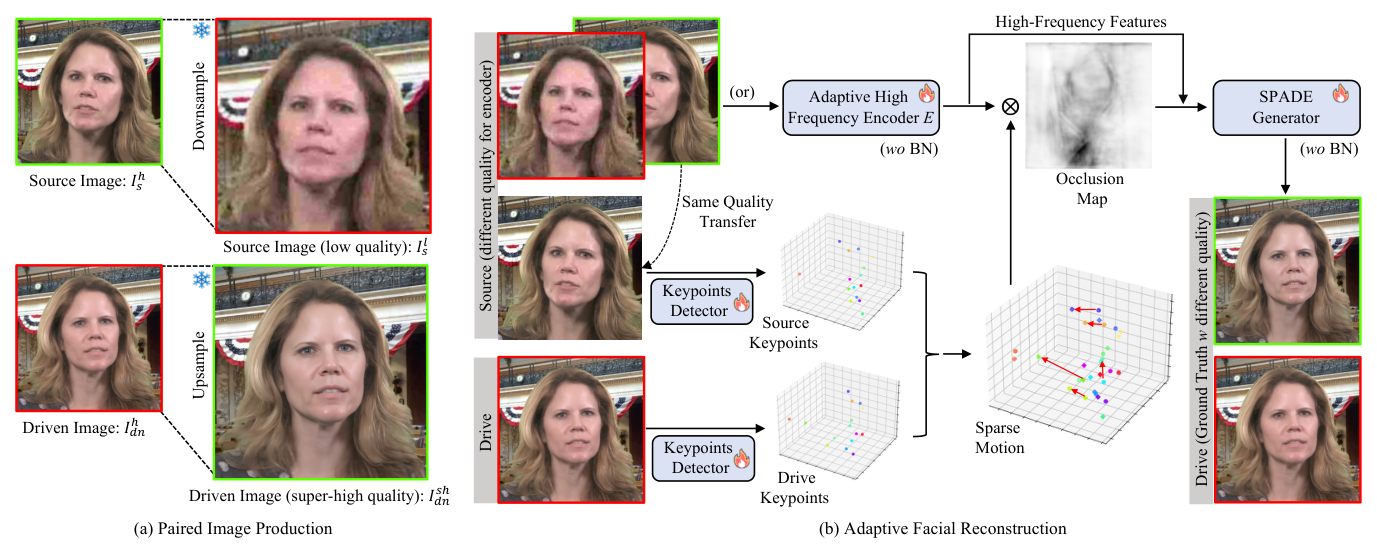
Adaptive Super Resolution for One-Shot Talking-Head Generation
Luchuan Song, Pinxin Liu, Guojun Yin, Chenliang Xu
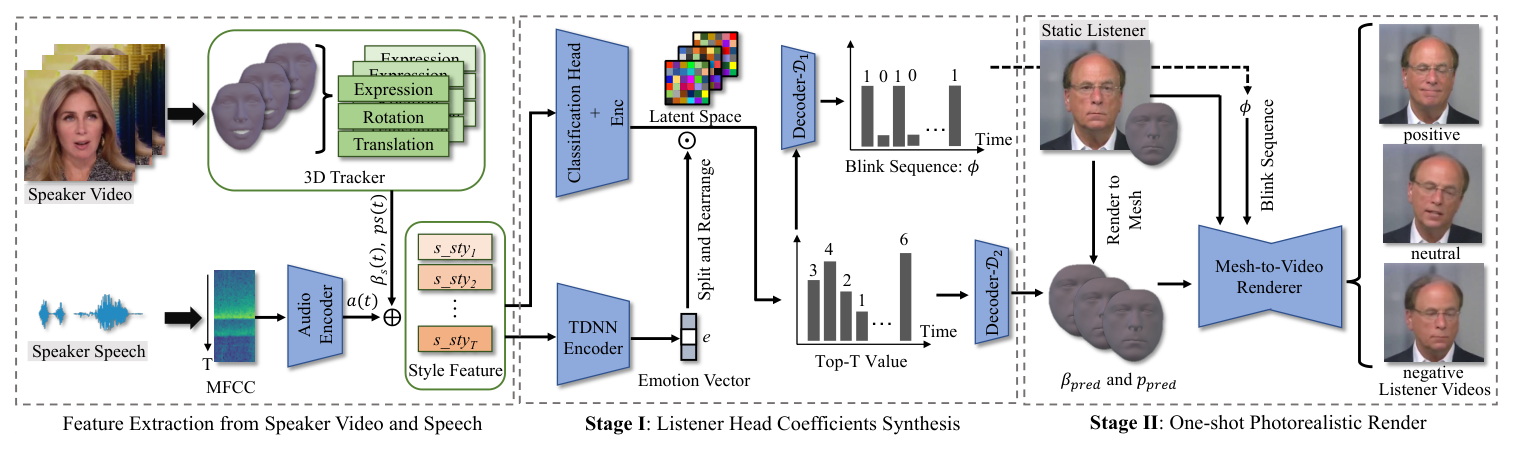
Emotional Listener Portrait: Realistic Listener Motion Simulation in Conversation
Luchuan Song, Guojun Yin, Zhenchao Jin, Xiaoyi Dong, Chenliang Xu
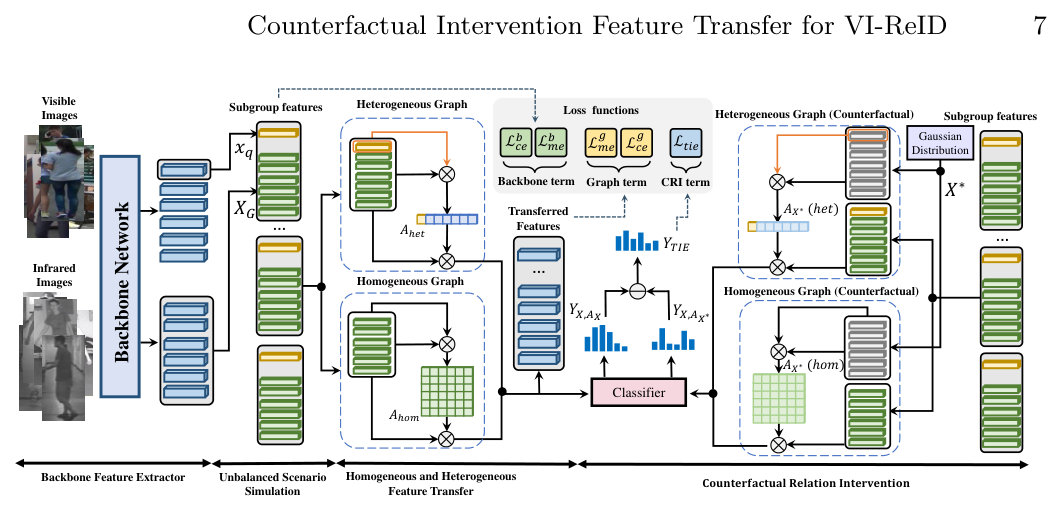
Counterfactual Intervention Feature Transfer for Visible-Infrared Person Re-identification
Xulin Li, Yan Lu, Bin Liu, Yating Liu, Guojun Yin, Qi Chu, Jinyang Huang, Feng Zhu, Rui Zhao, Nenghai Yu
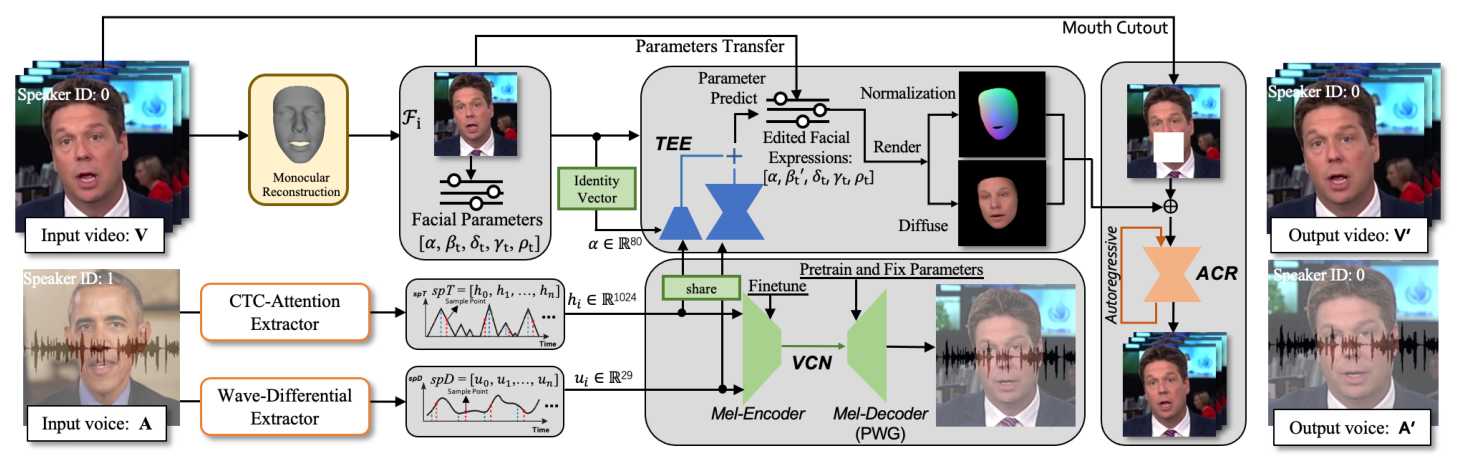
TACR-Net: Editing on Deep Video and Voice Portraits
Luchuan Song, Bin Liu, Guojun Yin, Xiaoyi Dong, Yufei Zhang, Jiaxu Bai
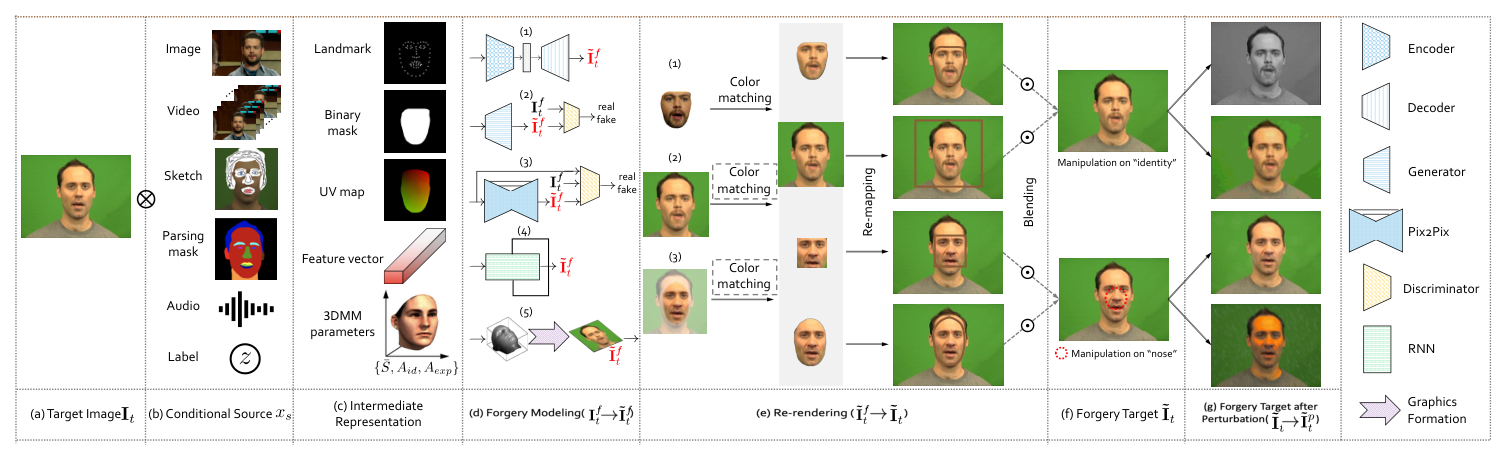
ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis
Yinan He, Bei Gan, Siyu Chen, Yichun Zhou, Guojun Yin, Luchuan Song, Lu Sheng, Jing Shao, Ziwei Liu
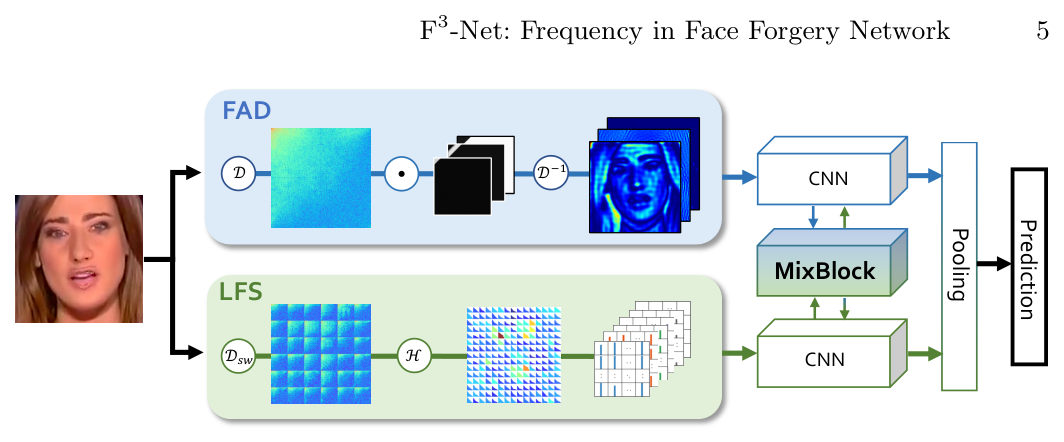
Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues
Yuyang Qian*, Guojun Yin*#, Lu Sheng#, Zixuan Chen*, Jing Shao

CelebA-Spoof: Large-Scale Face Anti-Spoofing Dataset with Rich Annotations
Yuanhan Zhang, Zhenfei Yin, Yidong Li, Guojun Yin, Junjie Yan, Jing Shao, Ziwei Liu
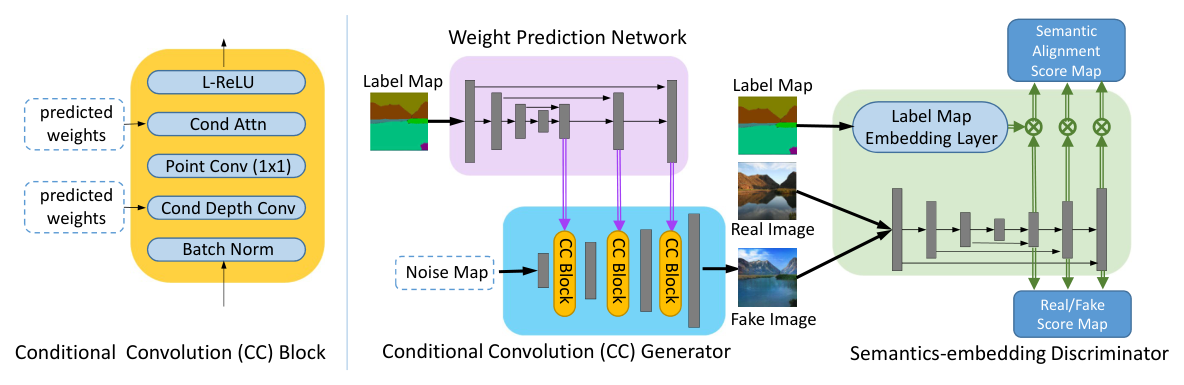
Learning to Predict Layout-to-image Conditional Convolutions for Semantic Image Synthesis
Xihui Liu, Guojun Yin, Jing Shao, Xiaogang Wang, Hongsheng Li
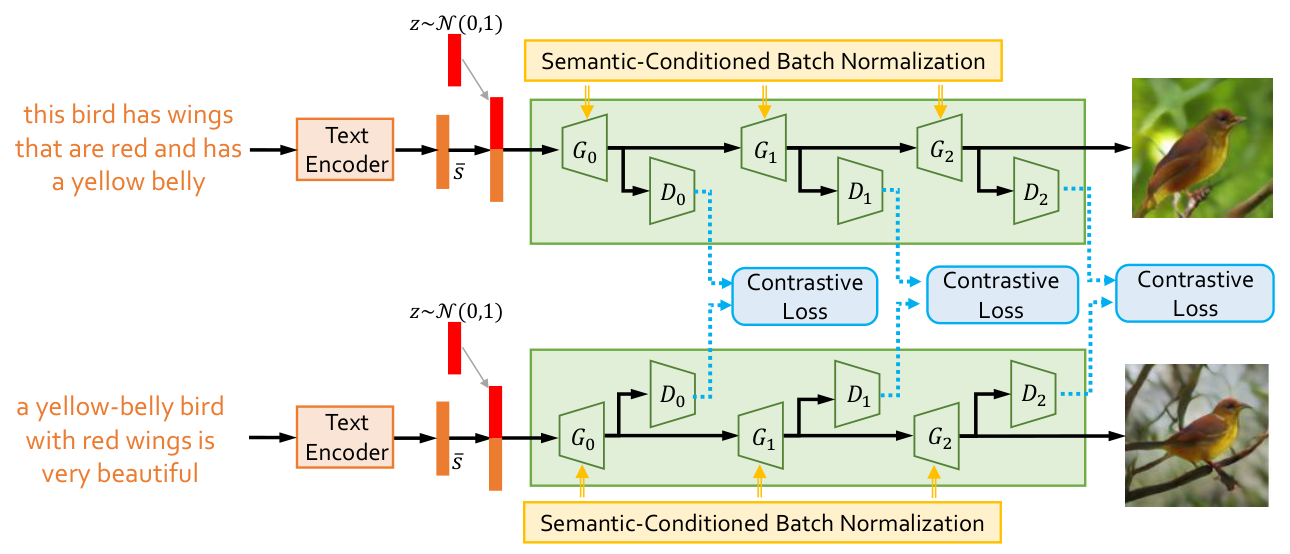
Semantics Disentangling for Text-to-Image Generation
Guojun Yin, Bin Liu, Lu Sheng, Nenghai Yu, Xiaogang Wang, Jing Shao
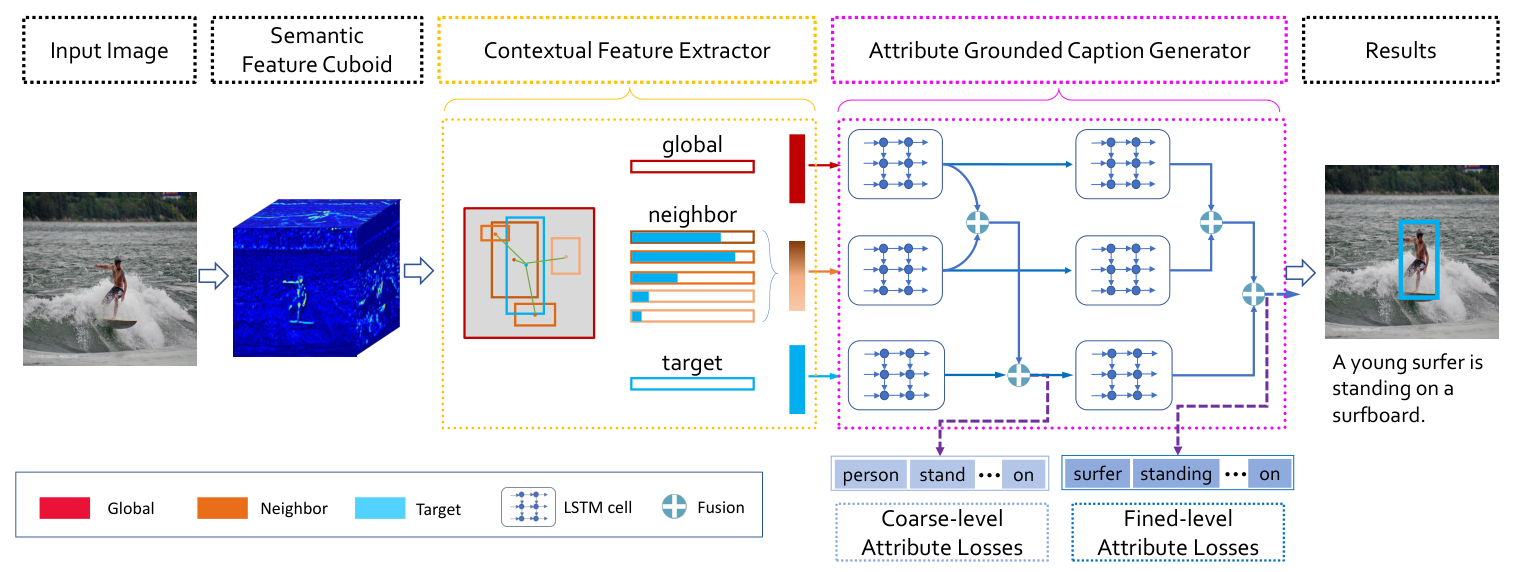
Context and Attribute Grounded Dense Captioning
Guojun Yin, Lu Sheng, Bin Liu, Nenghai Yu, Xiaogang Wang, Jing Shao
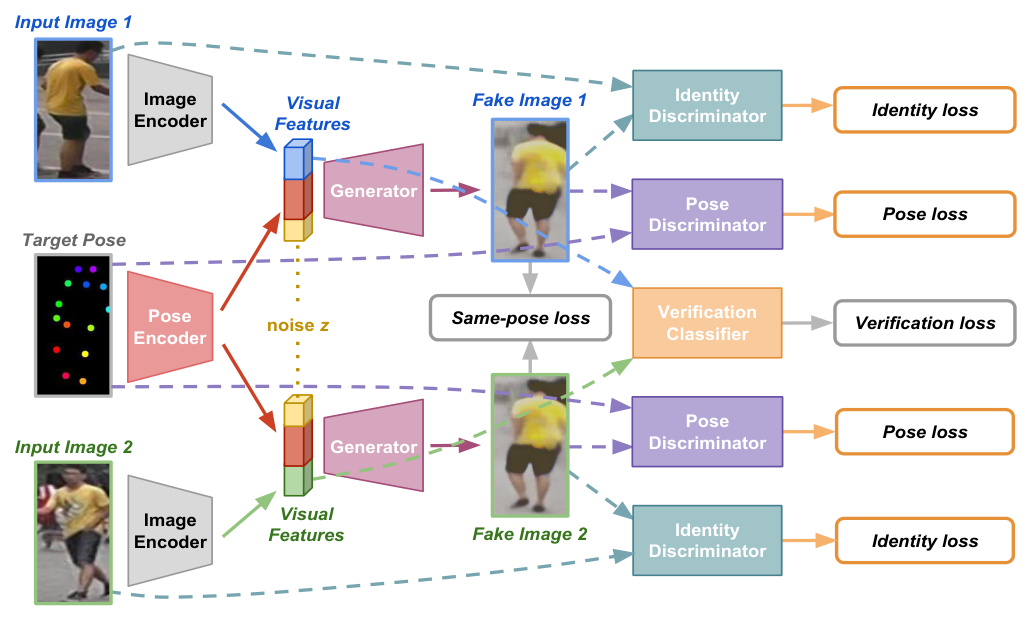
FD-GAN: Pose-guided Feature Distilling GAN for Robust Person Re-identification
Yixiao Ge*, Zhuowan Li*, Haiyu Zhao, Guojun Yin, Shuai Yi, Xiaogang Wang, Hongsheng Li
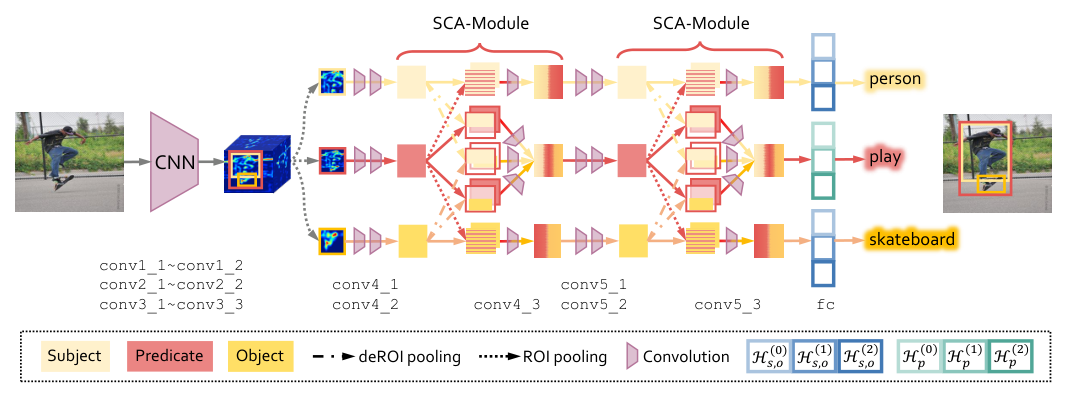
Zoom-Net: Mining Deep Feature Interactions for Visual Relationship Recognition
Guojun Yin, Lu Sheng, Bin Liu, Nenghai Yu, Xiaogang Wang, Jing Shao, Chen Change Loy
Education
Ph.D.
EE, USTC
2014.09 - 2019.07
Hefei
Research Assistant
2017.06 - 2018.09
Hong Kong
Bachelor
EE, USTC
2010.09 - 2014.06
Hefei
